- жөҸи§Ҳ: 665363 ж¬Ў
-

ж–Үз« еҲҶзұ»
зӨҫеҢәзүҲеқ—
- жҲ‘зҡ„иө„и®Ҝ ( 0)
- жҲ‘зҡ„и®әеқӣ ( 0)
- жҲ‘зҡ„й—®зӯ” ( 0)
еӯҳжЎЈеҲҶзұ»
- 2012-03 ( 4)
- 2012-02 ( 148)
- 2012-01 ( 50)
- жӣҙеӨҡеӯҳжЎЈ...
жңҖж–°иҜ„и®ә
-
zhlfresh163.comпјҡ
"var tilelayer=new BMap.Ti ...
зҷҫеәҰең°еӣҫAPIзҡ„еӯҰд№ -
йҷҲдҝ®жҒ’пјҡ
http://software.tangent.org/pro ...
mod_mp3и®©apacheжҲҗдёәжөҒеӘ’дҪ“жңҚеҠЎеҷЁ -
cjb20103163пјҡ
е—Ҝ еҫҲдёҚй”ҷВ иөһдёҖдёӘ
ж•°з»„ -
wengeldoubleпјҡ
[color=darkblue][/color]жҘјдё»еҶҷеҫ—еҫҲеҘҪ ...
зҲ¶зұ»зҡ„еј•з”ЁжҢҮеҗ‘еӯҗзұ»еҜ№иұЎ -
е®үд№ӢиӢҘзҙ пјҡ
еӣәжү§гҖҒеҶ·ж·ЎгҖҒеҸҚеә”иҝҹй’қгҖҒиҮӘжҒӢгҖҒзҗҶжғідё»д№үгҖҒ
зЁӢеәҸе‘ҳзҡ„зү№еҲ«
дҪҝз”ЁеҪ’зәіжі•и®ҫи®Ўз®—жі•
USING INDUCTION TO DESIGN дҪҝз”ЁеҪ’зәіжі•и®ҫи®Ўз®—жі•гҖҗе…Ёж–Үзҝ»иҜ‘гҖ‘
by Elton on дёғ.27, 2011, under жңӘеҲҶзұ»
еңЁж•°еӯҰе®ҡзҗҶиҜҒжҳҺе’Ңи®Ўз®—жңәз®—жі•и®ҫи®Ўд№Ӣй—ҙйҮҮз”Ёзұ»жҜ”зҡ„жҖқжғіиғҪеӨҹдёәз®—жі•и®ҫи®ЎжҸҗдҫӣдёҖдёӘжһҒеҘҪзҡ„ж–№жі•пјҢйҖҡиҝҮи§ЈйҮҠиҝҷз§ҚеҒҡжі•жқҘдәҶи§Јиҝҷз§Қе…ій”®жҖқжғіпјҢд»ҺиҖҢеҜ№жӯӨжңүжӣҙж·ұзҡ„зҗҶи§ЈгҖӮ
иҝҷзҜҮж–Үз« еңЁиҝӣиЎҢз»„еҗҲз®—жі•и®ҫи®Ўе’Ңж•ҷеӯҰиҝҮзЁӢдёӯеұ•зӨәдәҶдёҖз§ҚеҹәдәҺж•°еӯҰеҪ’зәіжі•зҡ„ж–№жі•пјҢе°Ҫз®Ўиҝҷз§Қ方法并дёҚиғҪж¶өзӣ–и®ҫи®Ўз®—жі•ж—¶зҡ„жүҖжңүеҸҜиғҪж–№жі•пјҢдҪҶе®ғеҢ…еҗ«дәҶеӨ§йғЁеҲҶе·ІзҹҘзҡ„жҠҖжңҜж–№жі•гҖӮеҗҢж—¶иҝҷз§Қж–№жі•д№ҹжҸҗдҫӣдәҶдёҖдёӘжһҒеҘҪзҡ„并且д№ҹжҳҜзӣҙи§Ӯзҡ„з»“жһ„пјҢд»ҺиҖҢеңЁи§ЈйҮҠз®—жі•и®ҫи®Ўзҡ„ж—¶еҖҷжҳҫеҫ—жӣҙжңүж·ұеәҰгҖӮиҝҷз§Қж–№жі•зҡ„ж ёеҝғжҳҜйҖҡиҝҮеҜ№ж•°еӯҰе®ҡзҗҶиҜҒжҳҺиҝҮзЁӢдёӯе’Ңи®ҫи®Ўз»„еҗҲз®—жі•иҝҮзЁӢдёӯзҡ„дёӨз§ҚжҷәеҠӣиҝҮзЁӢиҝӣиЎҢзұ»жҜ”гҖӮе°Ҫз®ЎжҲ‘们жүҝи®ӨиҝҷдёӨз§ҚиҝҮзЁӢжҳҜдёәдёҚеҗҢзҡ„зӣ®зҡ„жңҚеҠЎзҡ„并且еҸ–еҫ—зҡ„жҳҜдёҚеҗҢзұ»еһӢзҡ„з»“жһңпјҢдҪҶжҳҜиҝҷдёӨиҖ…иҰҒжҜ”зңӢдёҠеҺ»зҡ„жӣҙеҠ зӣёдјјгҖӮиҝҷз§ҚиҜҙжі•еҸҜд»ҘйҖҡиҝҮдёҖзі»еҲ—зҡ„з®—жі•дҫӢеӯҗеҫ—еҲ°йӘҢиҜҒпјҢеңЁиҝҷдәӣз®—жі•дёӯйғҪеҸҜд»ҘйҮҮз”Ёиҝҷз§Қж–№жі•иҝӣиЎҢи®ҫи®Ўе’Ңи§ЈйҮҠгҖӮжҲ‘们зӣёдҝЎйҖҡиҝҮеӯҰд№ иҝҷз§Қж–№жі•пјҢеӯҰз”ҹиғҪеӨҹеҜ№з®—жі•дә§з”ҹжӣҙеӨҡзҡ„зғӯжғ…пјҢд№ҹиғҪжӣҙж·ұе…ҘжӣҙеҘҪзҡ„зҗҶи§Јз®—жі•гҖӮ
ж•°еӯҰеҪ’зәіжі•жҳҜдёҖдёӘйқһеёёејәеӨ§зҡ„иҜҒжҳҺж–№жі•гҖӮдҪҝз”ЁеҰӮдёӢпјҡи®©TжҳҜдёҖдёӘжҲ‘们жғіиҜҒжҳҺзҡ„е®ҡзҗҶгҖӮеҒҮи®ҫTеҢ…еҗ«дёҖдёӘеҖјеҸҜдёәд»»ж„ҸиҮӘ然数зҡ„еҸӮж•°nгҖӮжҲ‘们дёҚйңҖиҰҒзӣҙжҺҘиҜҒжҳҺTеҜ№жүҖжңүзҡ„nйғҪжҲҗз«ӢпјҢжҲ‘们еҸӘйңҖиҰҒиҜҒжҳҺд»ҘдёӢдёӨзӮ№пјҡпјҲ1пјүTеҜ№n=1ж—¶жҲҗз«Ӣ пјҲ2пјүеҜ№дәҺд»»ж„Ҹзҡ„n>1пјҢTеҜ№дәҺn-1жҲҗз«ӢгҖӮ第дёҖзӮ№еҫҖеҫҖеҫҲе®№жҳ“иҜҒжҳҺпјҢиҜҒжҳҺ第дәҢзӮ№еңЁеҫҲеӨҡжғ…еҶөдёӢиҰҒжҜ”зӣҙжҺҘиҜҒжҳҺе®ҡзҗҶиҰҒе®№жҳ“пјҢеӣ дёәжӯӨж—¶жҲ‘们еҸҜд»ҘеҒҮи®ҫTеҜ№n-1е·Із»ҸжҲҗз«ӢгҖӮпјҲд»Һжҹҗз§Қж„Ҹд№үдёҠжқҘиҜҙпјҢжҲ‘д»¬ж— жқЎд»¶зҡ„иҺ·еҫ—иҝҷдёҖеҒҮи®ҫпјүгҖӮжҚўеҸҘиҜқиҜҙпјҢеҮҸе°Ҹе®ҡзҗҶзҡ„规模дҪҝз”ЁдёҖдёӘжӣҙе°Ҹзҡ„nеҖјиҖҢдёҚжҳҜд»ҺеӨҙејҖе§ӢиҜҒжҳҺжҳҜеҫҲжңүеё®еҠ©зҡ„пјҢжҲ‘们关注зҡ„е°ұжҳҜиҝҷз§ҚеҮҸе°ҸгҖӮ
иҝҷдёҖеҺҹеҲҷеҜ№дәҺз®—жі•еҗҢж ·д№ҹйҖӮз”ЁгҖӮеҪ’зәіжі•и®©дәә们关注дәҺд»Һиҫғе°Ҹзҡ„еӯҗй—®йўҳ延伸еҲ°йӮЈдәӣжӣҙеӨ§зҡ„й—®йўҳдёҠгҖӮеҸҜд»ҘйҖҡиҝҮд»Һй—®йўҳзҡ„д»»ж„ҸдёҖдёӘе®һдҫӢе…ҘжүӢпјҢйҖҡиҝҮеҒҮи®ҫ规模иҫғе°Ҹзҡ„зӣёеҗҢй—®йўҳе·Із»Ҹеҫ—еҲ°и§ЈеҶіпјҢ然еҗҺеҶҚиҜ•еӣҫи§ЈеҶіиҜҘй—®йўҳгҖӮдҫӢеҰӮпјҢз»ҷе®ҡдёҖдёӘnпјҲn>1пјүзҡ„еәҸеҲ—еҜ№е…¶иҝӣиЎҢжҺ’еәҸпјҲжҺ’еәҸдёҖдёӘеәҸеҲ—жҳҫ然没еҝ…иҰҒпјүпјҢжҲ‘们еҸҜд»ҘеҒҮе®ҡе·Із»ҸзҹҘйҒ“еҰӮдҪ•еҜ№n-1дёӘж•°иҝӣиЎҢжҺ’еәҸгҖӮ然еҗҺжҲ‘们еҸҜд»ҘиҰҒд№ҲжҺ’еәҸеүҚn-1дёӘж•°пјҢ然еҗҺжҠҠ第nдёӘж•°жҸ’е…ҘеҲ°жӯЈзЎ®дҪҚзҪ®пјҲиҝҷеј•еҮәдәҶдёҖдёӘеҸ«жҸ’е…ҘжҺ’еәҸзҡ„з®—жі•пјүпјҢиҰҒд№ҲдёҖејҖе§ӢжҠҠ第nдёӘж•°ж”ҫеңЁе®ғзҡ„жңҖз»ҲдҪҚзҪ®з„¶еҗҺеҶҚжҺ’еәҸеү©дёӢзҡ„ж•°пјҲиҝҷеј•еҮәдәҶдёҖдёӘеҸ«йҖүжӢ©жҺ’еәҸзҡ„з®—жі•пјүгҖӮжҲ‘们еҸӘйңҖиҰҒи§ЈеҶіеҜ№з¬¬nдёӘж•°зҡ„ж“ҚдҪңпјҲеҪ“然иҝҷ并дёҚжҳҜе”ҜдёҖзҡ„жҺ’еәҸж–№жі•пјҢд№ҹдёҚжҳҜе”ҜдёҖдёҖз§ҚдҪҝз”ЁеҪ’зәіжі•иҝӣиЎҢжҺ’еәҸзҡ„ж–№жі•пјүгҖӮ
дёҠйқўд»Ӣз»Қзҡ„дҪҝз”ЁеҪ’зәіжі•зҡ„дҫӢеӯҗеҫҲзӣҙи§ӮпјҢ然еҗҺжңүи®ёеӨҡдёҚеҗҢзҡ„ж–№жі•жқҘдҪҝз”ЁеҪ’зәіжі•пјҢз”ұжӯӨеёҰжқҘдәҶдёҚеҗҢзҡ„з®—жі•и®ҫи®ЎжҠҖе·§гҖӮиҝҷжҳҜдёҖдёӘйқһеёёејәеӨ§е’ҢзҒөжҙ»зҡ„ж–№жі•гҖӮжҲ‘们е°ҶиҜҒжҳҺпјҢеңЁдҪҝз”Ёиҝҷз§Қжғіжі•ж—¶еҫҲеӨҡй—®йўҳеҸҳеҫ—еҫҲз®ҖеҚ•пјҢиҝҷдёҖзӮ№дјҡи®©дҪ жғҠ讶дёҚе·ІгҖӮжҲ‘们е°ҶйҮҮз”Ёе…¶дёӯзҡ„еҮ з§Қж–№жі•пјҢ并жҳҫзӨәе®ғ们еңЁи®ҫи®Ўз®—жі•ж—¶зҡ„ејәеӨ§еҠӣйҮҸгҖӮеңЁжҲ‘们讨и®әзҡ„еҪ’зәіжі•зҡ„еҗ„з§ҚеҸҳеҪўж–№жі•дёӯпјҢжҲ‘们主иҰҒи®Ёи®әе·§еҰҷзҡ„йҖүжӢ©еҪ’зәіеәҸеҲ—пјҢеўһејәеҪ’зәіеҒҮи®ҫпјҢжӣҙејәзҡ„еҪ’зәіжі•д»ҘеҸҠжңҖеӨ§зҡ„еҸҚдҫӢеӣӣз§Қж–№жі•гҖӮ
жҲ‘们зҡ„еӨ„зҗҶж–№жі•жңүдёӨз§Қж–°еҘҮд№ӢеӨ„гҖӮйҰ–е…ҲжҲ‘们жҠҠзңӢдёҠеҺ»дёҚеҗҢзҡ„з®—жі•и®ҫи®ЎжҠҖжңҜеҪ’еҲ°еҗҢдёҖдёӘзұ»еҲ«дёӢпјҢиҝҷе°ҶдҪҝеҫ—еҜ№дёҖдёӘж–°з®—жі•зҡ„жҹҘжүҫжӣҙжңүжқЎзҗҶжҖ§гҖӮе…¶ж¬ЎпјҢжҲ‘们еҲ©з”Ёе·ІзҹҘзҡ„ж•°еӯҰиҜҒжҳҺжҠҖе·§жқҘи®ҫи®Ўз®—жі•пјҢиҝҷдёҖзӮ№еҫҲйҮҚиҰҒпјҢеӣ дёәе®ғејҖеҗҜдәҶеҲ©з”ЁеңЁеҲ«зҡ„еӯҰ科еӨҡе№ҙеҸ‘еұ•иҝҮзЁӢдёӯеҪўжҲҗзҡ„ејәеӨ§зҡ„жҠҖжңҜиҝӣиЎҢз®—жі•и®ҫи®Ўзҡ„ж—¶д»ЈгҖӮ
дёҖиҲ¬иҖҢиЁҖпјҢеңЁз®—жі•йўҶеҹҹдҪҝз”ЁеҪ’зәіжі•е’Ңж•°еӯҰиҜҒжҳҺжҠҖ巧并дёҚжҳҜ第дёҖж¬Ўи§ҒеҲ°гҖӮеҪ’зәіжі•еңЁиҜҒжҳҺз®—жі•жӯЈзЎ®жҖ§дёҠе·Із»ҸдҪҝз”ЁдәҶеҫҲй•ҝж—¶й—ҙпјҢдәә们йҖҡиҝҮжҠҠеҜ№з®—жі•жү§иЎҢжӯҘйӘӨзҡ„ж–ӯиЁҖпјҢиҜҒжҳҺе®ғ们еңЁжңҖеҲқжғ…еҶөдёӢжҲҗз«Ӣе’Ңе®ғ们еңЁзү№е®ҡж“ҚдҪңжӯҘйӘӨдёӢдҝқжҢҒдёҚеҸҳз»“еҗҲиө·жқҘпјҢд»ҺиҖҢйӘҢиҜҒз®—жі•зҡ„жӯЈзЎ®жҖ§гҖӮиҝҷз§Қж–№жі•жңҖеҲқз”ұе“Ҙзү№ж–Ҝе’ҢеҶҜиҜәдҫқжӣјжҸҗеҮәзҡ„пјҢеҗҺжқҘз”ұеј—жҙӣдјҠеҫ·е’Ңе…¶д»–дәәеҜ№е…¶иҝӣдёҖжӯҘеҸ‘еұ•гҖӮDijkstraе’Ңж јйҮҢж–ҜжҸҗеҮәдәҶдёҖз§Қе’ҢжҲ‘们ејҖеҸ‘зЁӢеәҸзӣёдјјзҡ„ж–№жі•пјҢеҗҢ时他们д№ҹз»ҷеҮәдәҶеҜ№е…¶жӯЈзЎ®жҖ§зҡ„иҜҒжҳҺгҖӮе°Ҫз®ЎеңЁжӯӨжҲ‘们еҖҹйүҙдәҶ他们зҡ„дёҖдәӣжҠҖжңҜпјҢдҪҶжҲ‘们зҡ„йҮҚзӮ№еҚҙдёҚеҗҢпјҡжҲ‘们关注дәҺй«ҳеұӮж¬Ўзҡ„з®—жі•зҗҶеҝөиҖҢдёҚеҝ…дёӢйҷҚеҲ°е®һйҷ…зҡ„зЁӢеәҸеұӮйқўгҖӮPRLе’ҢNuPRLпјҲиҝҷйҮҢдёҚдјҡзҝ»иҜ‘пјҢе»әи®®зңӢhttp://www.cs.cornell.edu/info/projects/nuprl/book/node2.htmlпјүдҪҝз”Ёж•°еӯҰиҜҒжҳҺдҪңдёәдёҖдёӘзЁӢеәҸејҖеҸ‘зі»з»ҹзҡ„еҹәжң¬жһ„жҲҗгҖӮеҪ“然йҖ’еҪ’д№ҹиў«е№ҝжіӣз”ЁдәҺз®—жі•и®ҫи®Ўд№ӢдёӯпјҲеҜ№дәҺйҖ’еҪ’зҡ„иҜҰз»Ҷи®Ёи®әиҜ·зңӢвҖҰпјү
жҲ‘们зҡ„зӣ®ж Үдё»иҰҒжҳҜз”ЁдәҺж•ҷеӯҰпјҢжҲ‘们еҒҮи®ҫиҜ»иҖ…еҜ№ж•°еӯҰеҪ’зәіжі•е’Ңеҹәжң¬зҡ„ж•°жҚ®з»“жһ„е·Із»ҸеҫҲзҶҹжӮүгҖӮеҜ№дәҺд»»ж„ҸдёҖз§ҚиҜҒжҳҺжҠҖе·§жҲ‘们дјҡеҜ№е…¶зұ»жҜ”иҝӣиЎҢдёҖдёӘз®ҖиҰҒзҡ„и§ЈйҮҠпјҢ然еҗҺз»ҷеҮәдёҖдёӘжҲ–еӨҡдёӘз®—жі•дҫӢеӯҗгҖӮеҜ№дәҺз»ҷеҮәзҡ„з®—жі•дҫӢеӯҗжҲ‘们йҮҚзӮ№е…іжіЁдәҺеҰӮдҪ•дҪҝз”Ёиҝҷз§Қж–№жі•гҖӮжҲ‘们зҡ„зӣ®зҡ„дёҚжҳҜеңЁдәҺеҜ№дёҖдёӘз®—жі•иҝӣиЎҢи§ЈйҮҠд»ҺиҖҢеё®еҠ©дёҖдёӘзЁӢеәҸе‘ҳжӣҙе®№жҳ“ең°е°Ҷе…¶иҪ¬жҚўдёәзЁӢеәҸпјҢиҖҢжҳҜйҖҡиҝҮдёҖз§Қжӣҙе®№жҳ“зҗҶи§Јзҡ„ж–№ејҸеҜ№е…¶иҝӣиЎҢи§ЈйҮҠгҖӮиҝҷдәӣз®—жі•йҖҡиҝҮдёҖз§ҚеҲӣйҖ жҖ§зҡ„иҝҮзЁӢеҠ д»Ҙи§ЈйҮҠиҖҢдёҚжҳҜд»ҘдёҖз§ҚжҲҗе“Ғзҡ„ж–№ејҸеҮәзҺ°гҖӮжҲ‘们ж•ҷз®—жі•зҡ„зӣ®ж ҮдёҚд»…д»…жҳҜеҗ‘еӯҰз”ҹеұ•зӨәеҰӮдҪ•и§ЈеҶіеҪ“еүҚзү№е®ҡзҡ„й—®йўҳпјҢеҗҢж—¶д№ҹжҳҜеё®еҠ©д»–们解еҶіжңӘжқҘж–°зҡ„й—®йўҳгҖӮж•ҷеӯҰз”ҹеҰӮдҪ•жҠҠжғіжі•иһҚе…ҘеҲ°з®—жі•и®ҫи®Ўдёӯе’Ңж•ҷеӯҰз”ҹи§ЈеҶіж–№жЎҲзҡ„е®һзҺ°з»ҶиҠӮеҗҢж ·йҮҚиҰҒгҖӮдҪҶеүҚиҖ…йҖҡеёёиҰҒжӣҙйҡҫдёҖдәӣгҖӮжҲ‘们зӣёдҝЎжҲ‘们зҡ„ж–№жі•иғҪеӨҹеҠ ејәеҜ№иҝҷз§ҚжҖқз»ҙиҝҮзЁӢзҡ„зҗҶи§ЈгҖӮ
е°Ҫз®ЎеҪ’зәіжі•е»әи®®йҖҡиҝҮйҖ’еҪ’еҠ д»Ҙе®һзҺ°пјҢдҪҶд№ҹжңӘеҝ…еҰӮжӯӨгҖӮпјҲдәӢе®һдёҠжҲ‘们称иҝҷз§Қж–№жі•дёәеҪ’зәіиҖҢдёҚжҳҜйҖ’еҪ’пјҢд»ҺиҖҢж·ЎеҢ–йҖ’еҪ’е®һзҺ°зҡ„жҰӮеҝөпјүеңЁеҫҲеӨҡжғ…еҶөдёӢпјҢиҝӯд»Јд№ҹеҫҲе®№жҳ“пјҢз”ҡиҮіе°Ҫз®ЎеңЁз®—жі•и®ҫи®ЎдёӯжҲ‘们еҝғйҮҢжғізҡ„жҳҜдҪҝз”ЁеҪ’зәіжі•пјҲйҖ’еҪ’пјүпјҢдҪҶиҝӯд»ЈеҚҙжӣҙжңүж•ҲзҺҮгҖӮ
жң¬ж–ҮдёӯжҸҗеҲ°зҡ„иҝҷдәӣз®—жі•жҳҜз»ҸиҝҮзӯӣйҖүзҡ„пјҢд»ҘдҫҝиғҪжӣҙеҘҪзҡ„еұ•зҺ°иҝҷз§Қж–№жі•зҡ„йӯ…еҠӣгҖӮжҲ‘们йҖүжӢ©зҡ„жҳҜдёҖдәӣз®ҖеҚ•зҡ„й—®йўҳпјҢеңЁеҗҺз»ӯйғЁеҲҶйҖүжӢ©дёҖдәӣжӣҙеӨҚжқӮзҡ„дҫӢеӯҗгҖӮжҲ‘们еҸ‘зҺ°еҫҲеӨҡеӣәе®ҡзҡ„з®—жі•еңЁз®—жі•и®ҫи®ЎиҜҫдёҠ第дёҖж¬Ўж•ҷжҺҲж—¶еҸҜд»ҘдҪҝз”Ёиҝҷз§Қж–№жі•гҖӮпјҲдҪҝз”Ёиҝҷз§Қж–№жі•зҡ„з®—жі•еҜји®әд№ҰеҫҲеҝ«е°ұиҰҒеҮәжқҘдәҶпјүжҲ‘们йҰ–е…Ҳд»ҺдёүдёӘз®ҖеҚ•зҡ„дҫӢеӯҗе…ҘжүӢпјҢпјҲиҮіе°‘дҪҝз”ЁеҪ’зәіжі•и®©д»–们зңӢдёҠеҺ»з®ҖеҚ•дәҶпјү然еҗҺжҲ‘们еұ•зӨәдёҖдәӣж•°еӯҰиҜҒжҳҺжҠҖе·§д»ҘеҸҠе®ғ们еңЁз®—жі•и®ҫи®Ўдёӯзұ»дјјзҡ„жҠҖе·§пјҢеңЁжҜҸз§Қжғ…еҶөдёӢиҝҷз§Қзұ»жҜ”йғҪеңЁдёҖдёӘжҲ–еӨҡдёӘдҫӢеӯҗдёӯеҫ—еҲ°дәҶйҳҗжҳҺгҖӮ
дёүдёӘдҫӢеӯҗ
и®Ўз®—еӨҡйЎ№ејҸзҡ„еҖјгҖҗQ1гҖ‘
й—®йўҳпјҡз»ҷе®ҡдёҖдёӘе®һж•°еәҸеҲ—an,an-1,вҖҰa1,a0е’ҢдёҖдёӘе®һж•°xпјҢи®Ўз®—дёӢйқўиҝҷдёӘеӨҡйЎ№ејҸзҡ„еҖј
Pn(x)=an*x^n+an-1*x^(n-1)+вҖҰa1*x+a0
иҝҷдёӘй—®йўҳзңӢдёҠеҺ»е№¶дёҚеғҸжҳҜдёҖдёӘдҪҝз”ЁеҪ’зәіжі•жұӮи§Јзӣҙи§ӮдҫӢеӯҗпјҢе°Ҫз®ЎеҰӮжӯӨпјҢжҲ‘们е°ҶиҜҒжҳҺдҪҝз”ЁеҪ’зәіжі•иғҪеӨҹзӣҙжҺҘеёҰжқҘеҫҲдёҚй”ҷзҡ„и§ЈеҶіж–№жі•гҖӮжҲ‘们йҰ–е…ҲдҪҝз”ЁжңҖз®ҖеҚ•еҮ д№Һеҫ®дёҚи¶ійҒ“зҡ„ж–№жі•жұӮи§ЈпјҢ然еҗҺйҖҡиҝҮеҸ‘зҺ°е…¶дёӯзҡ„еҸҳеҢ–пјҢд»ҺиҖҢжүҫеҲ°жӣҙеҘҪзҡ„и§ЈеҶіж–№жЎҲгҖӮ
иҝҷдёӘй—®йўҳж¶үеҸҠеҲ°n+2дёӘж•°еӯ—гҖӮдҪҝз”ЁеҪ’зәіжі•и§ЈеҶіиҜҘй—®йўҳзҡ„дҫқжҚ®жҳҜеҜ№дёҖдёӘжӣҙе°Ҹзҡ„й—®йўҳиҝӣиЎҢжұӮи§ЈгҖӮжҚўеҸҘиҜқиҜҙпјҢжҲ‘们е°ҪйҮҸеҮҸе°Ҹй—®йўҳзҡ„规模пјҢ然еҗҺдҪҝз”ЁйҖ’еҪ’жұӮи§ЈгҖӮпјҲжҲ–иҖ…жҲ‘们称其дёәеҪ’зәіпјү第дёҖжӯҘе°қиҜ•жҳҜ移йҷӨanпјҢиҝҷе°ҶеҜјиҮҙй—®йўҳдёӯи®Ўз®—зҡ„иЎЁиҫҫејҸеҸҳжҲҗпјҡ
Pn-1(x)=an-1*x^(n-1)+an-2*x^(n-2)+вҖҰ+a1*x+a0
йҷӨдәҶ规模еӨ–иҝҷжҳҜдёҖдёӘеҗҢж ·зҡ„й—®йўҳгҖӮеӣ жӯӨжҲ‘们еҸҜд»ҘдҪҝз”ЁдёӢйқўзҡ„еҒҮи®ҫиҝҗз”ЁеҪ’зәіжі•еҜ№е…¶иҝӣиЎҢжұӮи§Јпјҡ
еҪ’зәіеҒҮи®ҫпјҡжҲ‘们已з»ҸзҹҘйҒ“еҰӮдҪ•еҺ»и®Ўз®—дёҖдёӘеӨҡйЎ№ејҸпјҢиҜҘеӨҡйЎ№ејҸеңЁxеӨ„зҡ„иҫ“е…ҘйЎ№жңүan-1,вҖҰa1,a0пјҲеҚіжҲ‘们зҹҘйҒ“еҰӮдҪ•и®Ўз®—Pn-1(x)пјү
жҲ‘们зҺ°еңЁеҸҜд»ҘдҪҝз”ЁиҝҷеҒҮи®ҫиҝҗз”ЁеҪ’зәіжі•жқҘи§ЈеҶіиҜҘй—®йўҳгҖӮйҰ–е…ҲжҲ‘们йңҖиҰҒи§ЈеҶіжңҖеҹәжң¬зҡ„жғ…еҶөпјҢд№ҹе°ұжҳҜи®Ўз®—a0пјӣиҝҷжҳҜеҫҲз®ҖеҚ•зҡ„гҖӮ然еҗҺжҲ‘们еҝ…йЎ»иЎЁжҳҺеҰӮдҪ•йҖҡиҝҮеҖҹеҠ©и§„жЁЎиҫғе°Ҹзҡ„й—®йўҳзҡ„и§ЈеҶіж–№жЎҲпјҲиҝҷйҮҢжҳҜPn-1(x)зҡ„еҖјпјүжқҘи§ЈеҶіеҺҹжңүй—®йўҳпјҲеҚіи®Ўз®—Pn(x)пјүгҖӮеңЁиҜҘдҫӢеӯҗдёӯиҝҷжҳҜеҫҲзӣҙи§Ӯзҡ„гҖӮжҲ‘们仅仅йңҖиҰҒи®Ўз®—x^nпјҢд№ҳд»Ҙan然еҗҺеҠ дёҠPn-1(x)еҚіеҸҜгҖӮ
еңЁиҝҷдёҖзӮ№дёҠзңӢдёҠеҺ»дҪҝз”ЁеҪ’зәіжі•еҫҲж— иҒҠеӣ дёәе®ғд»…д»…жҳҜеӨҚжқӮдәҶдёҖдёӘз®ҖеҚ•зҡ„и§ЈеҶіж–№жЎҲпјҢдёҠйқўжҸҗеҲ°зҡ„з®—жі•д»…д»…жҳҜжҢүз…§еӨҡйЎ№ејҸзҡ„ж•°еӯҰж–№ејҸеҜ№еӨҡйЎ№ејҸд»ҺеҸіеҲ°е·ҰиҝӣиЎҢи®Ўз®—иҖҢе·ІгҖӮ然иҖҢпјҢжҲ‘们еҫҲеҝ«е°ұдјҡзңӢи§Ғиҝҷз§Қж–№жі•зҡ„ејәеӨ§д№ӢеӨ„гҖӮ
е°Ҫз®ЎиҝҷдёӘз®—жі•жҳҜжӯЈзЎ®зҡ„пјҢдҪҶ其并дёҚжҳҜй«ҳж•Ҳзҡ„гҖӮе®ғйңҖиҰҒn+n-1+n-2+вҖҰ+1=n(n+1)/2ж¬Ўд№ҳжі•е’Ңnж¬ЎеҠ жі•и®Ўз®—гҖӮзҺ°еңЁжҲ‘们з•Ҙеҫ®ж”№еҸҳдёҖдёӢеҪ’зәіжі•зҡ„дҪҝз”Ёж–№жі•пјҢд»ҺиҖҢеҫ—еҲ°дёҖдёӘжӣҙеҘҪзҡ„и§ЈеҶіж–№жЎҲгҖӮ
ж”№иҝӣпјҡ第дёҖдёӘж”№иҝӣд№ӢеӨ„еңЁдәҺжҲ‘们注ж„ҸеҲ°еңЁжұӮи§ЈиҝҮзЁӢдёӯеӯҳеңЁеҫҲеӨҡеҶ—дҪҷи®Ўз®—пјҡxзҡ„жҢҮж•°жҳҜд»ҺеӨҙејҖе§Ӣи®Ўз®—зҡ„гҖӮеҪ“жҲ‘们计算x^nж—¶йҖҡиҝҮдҪҝз”Ёx^(n-1)зҡ„еҖјиғҪеӨҹеё®жҲ‘们иҠӮзңҒеҫҲеӨҡд№ҳжі•иҝҗз®—гҖӮиҝҷдәӣйғҪжҳҜеңЁеҪ’зәіжі•еҒҮи®ҫдёӯйҖҡиҝҮеҜ№x^nи®Ўз®—зҡ„еҪ’зәіеҫ—д»Ҙе®һзҺ°зҡ„пјҡ
жӣҙејәзҡ„еҪ’зәіеҒҮи®ҫпјҡжҲ‘们已з»ҸзҹҘйҒ“дәҶеҰӮдҪ•еҺ»и®Ўз®—еӨҡйЎ№ејҸPn-1(x)пјҢеҗҢж—¶жҲ‘们д№ҹзҹҘйҒ“еҰӮдҪ•и®Ўз®—x^(n-1)зҡ„еҖјгҖӮ
иҝҷдёӘеҪ’зәіеҒҮи®ҫжӣҙејәдёҖдәӣпјҢеӣ дёәе®ғиҰҒжұӮи®Ўз®—еҮәx^(n-1)пјҢдҪҶжҳҜе®ғжӢ“еұ•иө·жқҘжӣҙе®№жҳ“гҖӮжҲ‘们еңЁи®Ўз®—x^nж—¶д»…д»…йңҖиҰҒиҝӣиЎҢдёҖжӯҘд№ҳжі•ж“ҚдҪңпјҢ然еҗҺеңЁиҝӣиЎҢдёҖжӯҘд№ҳжі•ж“ҚдҪңеҫ—еҲ°an*x^nпјҢ然еҗҺиҝӣиЎҢдёҖжӯҘеҠ жі•ж“ҚдҪңе®ҢжҲҗж•ҙдёӘи®Ўз®—гҖӮпјҲе…¶е®һиҝҷдёӘеҒҮи®ҫ并дёҚжҳҜеӨӘејәпјҢеӣ дёәжҲ‘们иҝҳжҳҜйңҖиҰҒи®Ўз®—x^(n-1)зҡ„еҖјпјүгҖӮжҖ»иҖҢиЁҖд№ӢпјҢиҝҷйҮҢйңҖиҰҒиҝӣиЎҢ2nж¬Ўд№ҳжі•е’Ңnж¬ЎеҠ жі•гҖӮе°Ҫз®ЎиҝҷдёӘеҪ’зәіеҒҮи®ҫйңҖиҰҒжӣҙеӨҡзҡ„и®Ўз®—пјҢдҪҶжҖ»зҡ„иҜҙжқҘе®ғеҮҸе°‘дәҶе·ҘдҪңйҮҸгҖӮжҲ‘们еңЁеҗҺйқўеҶҚжқҘи®Ёи®әиҝҷдёҖзӮ№гҖӮеңЁеҗ„з§ҚеұӮйқўдёҠзңӢжқҘиҝҷдёӘз®—жі•еҫҲеҘҪпјҢе®ғй«ҳж•ҲпјҢз®ҖеҚ•д№ҹе®№жҳ“е®һзҺ°гҖӮ然иҖҢеӯҳеңЁдёҖдёӘжӣҙеҘҪзҡ„з®—жі•пјҢе®ғжҳҜйҖҡиҝҮз”ЁдёҖз§ҚдёҚеҗҢзҡ„ж–№ејҸдҪҝз”ЁеҪ’зәіжі•еҫ—д»Ҙе®һзҺ°зҡ„гҖӮ
жҲ‘们йҖҡиҝҮ移еҺ»жңҖеҗҺдёҖдёӘзі»ж•°anжқҘз®ҖеҢ–й—®йўҳгҖӮпјҲиҝҷжҳҜдёҖдёӘеҫҲзӣҙжҲӘдәҶеҪ“зҡ„еҒҡжі•пјүдҪҶжҳҜжҲ‘们д№ҹеҸҜд»Ҙ移еҺ»з¬¬дёҖдёӘзі»ж•°a0гҖӮиҝҷдёӘ规模жӣҙе°Ҹзҡ„й—®йўҳеҸҳжҲҗдәҶи®Ўз®—з”ұan,an-1вҖҰa1иҝҷдәӣзі»ж•°з»„жҲҗзҡ„еӨҡйЎ№ејҸпјҢеҰӮдёӢжүҖзӨәпјҡ
PвҖҷn-1(x)=an*x^(n-1)+an-1*x^(n-2)вҖҰ+a1
пјҲжіЁж„ҸеҲ°anзҺ°еңЁжҳҜn-1ж¬Ўзҡ„зі»ж•°пјҢеҗҺйқўдҫқж¬Ўж”№еҸҳпјү
ж–°зҡ„еҪ’зәіеҒҮи®ҫпјҲеҖ’еәҸпјүпјҡжҲ‘们зҹҘйҒ“еҰӮдҪ•еҺ»и®Ўз®—з”ұзі»ж•°an,an-1вҖҰa1жһ„жҲҗзҡ„xеӨҡйЎ№ејҸпјҲеҚідёҠйқўеҲ—еҮәжқҘзҡ„PвҖҷn-1(x)пјү
з”ұдәҺиҝҷдёӘеҒҮи®ҫжӣҙе®№жҳ“жӢ“еұ•пјҢж•…е…¶жӣҙз¬ҰеҗҲжҲ‘们зҡ„зӣ®зҡ„гҖӮеҫҲжҳҺжҳҫPn(x)=x*PвҖҷn-1(x)+a0гҖӮеӣ жӯӨиҝҷйҮҢд»…д»…еҸӘиҰҒдёҖж¬Ўд№ҳжі•е’ҢдёҖж¬ЎеҠ жі•е°ұеҸҜд»ҘйҖҡиҝҮPвҖҷn-1(x)и®Ўз®—еҫ—еҮәPn(x)гҖӮе®Ңж•ҙзҡ„з®—жі•еҸҜд»ҘйҖҡиҝҮдёӢйқўиҝҷдёӘиЎЁиҫҫејҸеҠ д»ҘжҸҸиҝ°пјҡ
an*x^n+an-1*x^(n-1)+вҖҰ+a1*x+a0=((вҖҰ((an*x+an-1)x+an-2)вҖҰ)x+a1)x+a0
иҝҷдёӘз®—жі•иў«з§°дёәйңҚзәіеҪ’зәід»ҘW.G.Hornerе‘ҪеҗҚгҖӮпјҲиҝҷд№ҹжҳҜзүӣйЎҝжҸҗеҮәжқҘзҡ„пјүгҖӮдёӢйқўз»ҷеҮәдәҶи®Ўз®—еӨҡйЎ№ејҸзҡ„з®—жі•гҖӮ
и®Ўз®—иЎЁиҫҫејҸз®—жі•
(a0,a1,a2вҖҰan,x:real); //иҫ“е…Ҙa0иҮіan,x,е…Ёдёәе®һж•°
begin
P:=an;
for i:=1 to n do
P:=x*P+an-i;
end;
еӨҚжқӮеәҰпјҡиҝҷдёӘз®—жі•д»…д»…йңҖиҰҒnж¬Ўд№ҳжі•,nж¬ЎеҠ жі•д»ҘеҸҠдёҖдёӘйўқеӨ–зҡ„еҶ…еӯҳз©әй—ҙгҖӮе°Ҫз®ЎеҺҹе…Ҳзҡ„и§ЈеҶіж–№жі•зңӢдёҠеҺ»з®ҖеҚ•е№¶дё”й«ҳж•ҲпјҢдҪҶиҝҪжұӮдёҖдёӘжӣҙеҘҪзҡ„з®—жі•жҳҜеҖјеҫ—зҡ„гҖӮиҝҷдёӘз®—жі•дёҚд»…д»…жҳҜйҖҹеәҰжӣҙеҝ«пјҢеҗҢж—¶зӣёеә”зҡ„зЁӢеәҸд№ҹжӣҙз®ҖеҚ•гҖӮ
жҖ»з»“пјҡдёҠйқўз»ҷеҮәзҡ„з®ҖеҚ•дҫӢеӯҗйҳҗжҳҺдәҶеҪ’зәіжі•дҪҝз”ЁиҝҮзЁӢдёӯзҡ„зҒөжҙ»жҖ§гҖӮйңҚзәіи§„еҲҷзҡ„жҠҖе·§д»…еңЁдәҺиҖғиҷ‘еҲ°иҫ“е…ҘжҳҜд»Һе·Ұеҗ‘еҸізҡ„пјҢиҖҢдёҚжҳҜзӣҙи§ӮдёҠзңӢеҲ°зҡ„д»ҺеҸіеҗ‘е·ҰгҖӮ
еҪ“然иҝҷйҮҢжңүдҪҝз”ЁеҪ’зәіжі•зҡ„и®ёеӨҡе…¶д»–жҪңеңЁжҖ§пјҢжҲ‘们е°ҶеңЁжӣҙеӨҡзҡ„дҫӢеӯҗдёӯзңӢеҲ°иҝҷдёҖзӮ№
жүҫеҲ°дёҖдёҖжҳ е°„е…ізі»гҖҗQ2гҖ‘
fжҳҜдёҖдёӘжҠҠжңүйҷҗйӣҶеҗҲAжҳ е°„еҲ°е…¶иҮӘиә«зҡ„еҮҪж•°гҖӮпјҲдҫӢеҰӮAдёӯзҡ„жҜҸдёҖдёӘе…ғзҙ йғҪжҳ е°„еҲ°Aдёӯзҡ„еҸҰдёҖдёӘе…ғзҙ пјүдёәдәҶз®ҖеҢ–иө·и§ҒпјҢжҲ‘们жҠҠAдёӯзҡ„е…ғзҙ иЎЁзӨәдёәд»Һ1еҲ°nзҡ„ж•°еӯ—гҖӮжҲ‘们еҒҮе®ҡеҮҪж•°fд»ҘдёҖдёӘж•°з»„f[1..n]зҡ„еҪўејҸеҮәзҺ°пјҢиҝҷж ·f[i]еӯҳж”ҫзҡ„жҳҜf(i)зҡ„еҖјгҖӮпјҲиҜҘеҖјжҳҜдёҖдёӘдҪҚдәҺ1еҲ°nд№Ӣй—ҙзҡ„ж•ҙж•°пјүеҪ“Aдёӯзҡ„жҜҸдёҖдёӘе…ғзҙ йғҪд»…д»…еҸӘжңүдёҖдёӘе…ғзҙ еҜ№еә”е®ғж—¶жҲ‘们жҠҠеҮҪж•°fз§°дёәдёҖдёҖжҳ е°„гҖӮеҮҪж•°fеҸҜд»Ҙз”Ёеӣҫ1дёӯзҡ„еӣҫеҠ д»Ҙеұ•зӨәпјҢеңЁеӣҫдёӯпјҢдёӨз«Ҝж•°жҚ®йғҪеҜ№еә”еҗҢдёҖдёӘйӣҶеҗҲпјҢеӣҫдёӯзҡ„иҫ№иЎЁзӨәжҳ е°„е…ізі»гҖӮпјҲиҝҷз§Қжҳ е°„е…ізі»жҳҜд»Һе·ҰиҮіеҸізҡ„пјү
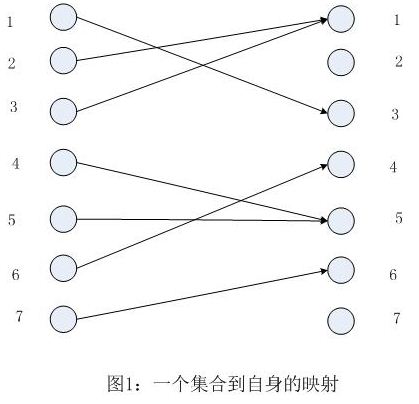
й—®йўҳпјҡжүҫеҲ°дёҖдёӘеҢ…еҗ«жңҖеӨҡе…ғзҙ зҡ„еӯҗйӣҶS(ScA)пјҢдҪҝеҫ—еҮҪж•°fиғҪеӨҹжҠҠSдёӯзҡ„д»»дҪ•е…ғзҙ жҳ е°„еҲ°Sдёӯзҡ„е…¶д»–е…ғзҙ гҖӮ(еҚіfи®©Sжҳ е°„еҲ°иҮӘиә«)пјҢеҗҢж—¶Sдёӯзҡ„жҜҸдёҖдёӘе…ғзҙ д»…д»…еҸӘжңүе”ҜдёҖзҡ„дёҖдёӘSдёӯзҡ„е…ғзҙ жҳ е°„еҲ°иҮӘиә«гҖӮпјҲеҚійҷҗеҲ¶Sи®©fжҲҗдёәдёҖдёӘдёҖдёҖжҳ е°„пјү
еҰӮжһңfжң¬жқҘе°ұжҳҜдёҖдёӘдёҖдёҖжҳ е°„пјҢйӮЈд№Ҳе…ЁйӣҶAе°ұж»Ўи¶ідәҶй—®йўҳзҡ„жқЎд»¶пјҢжҳҫ然е®ғд№ҹжҳҜжңҖеӨ§зҡ„йӣҶеҗҲгҖӮеңЁеҸҰдёҖдёӘж–№йқўжқҘиҜҙпјҢеҰӮжһңf(i)=f(j)еӯҳеңЁдё”iвү jпјҢйӮЈд№ҲйӣҶеҗҲSе°ұдёҚиғҪеҗҢж—¶еҢ…еҗ«iе’ҢjгҖӮдҫӢеҰӮеңЁеӣҫ1дёӯSе°ұдёҚиғҪеҗҢж—¶еҢ…еҗ«2е’Ң3гҖӮдёҚеҸҜиғҪд»»ж„Ҹд»ҺдёӨиҖ…дёӯйҖүжӢ©дёҖдёӘд»ҺйӣҶеҗҲдёӯеү”йҷӨеҮәеҺ»гҖӮдҫӢеҰӮпјҢеҒҮи®ҫжҲ‘们еҶіе®ҡеҲ еҺ»3пјҢз”ұдәҺ1иў«жҳ е°„еҲ°3пјҢжүҖд»ҘжҲ‘们д№ҹеҝ…йЎ»еҲ еҺ»1гҖӮпјҲеӣ дёәд»»ж„Ҹжҳ е°„еҝ…йЎ»жҳ е°„еҲ°SдёӯиҖҢжӯӨж—¶3е·Із»ҸдёҚеңЁSдёӯдәҶпјүгҖӮдҪҶжҳҜеҰӮжһң1иў«жҺ’йҷӨдәҶпјҢйӮЈд№Ҳ2д№ҹдјҡеӣ дёәеҗҢж ·зҡ„еҺҹеӣ иў«еҲ еҺ»гҖӮдҪҶжҳҜпјҢиҝҷж ·еҫ—еҲ°зҡ„з»“жһңйӣҶдёҚжҳҜжңҖеӨ§зҡ„пјҢеӣ дёәжҲ‘们еҫҲе®№жҳ“е°ұиғҪзңӢеҲ°еҸҜд»ҘеҸӘеҲ еҺ»2еҚіеҸҜгҖӮиҝҷдёӘй—®йўҳе…¶е®һжҳҜи®©жҲ‘们еҺ»жүҫеҲ°дёҖз§ҚйҖҡз”Ёзҡ„ж–№жі•жқҘеҶіе®ҡйӣҶеҗҲдёӯеҢ…еҗ«е“Әдәӣе…ғзҙ иҖҢе·ІгҖӮ
дҪҝз”ЁеҪ’зәіжі•жұӮи§Јзҡ„жҖқжғійӣҶдёӯеңЁзј©еҮҸй—®йўҳзҡ„规模дёҠпјҢиҝҷз§Қж–№жі•дҪҝз”Ёиө·жқҘд№ҹеҫҲзҒөжҙ»гҖӮжҲ‘们еҸҜд»ҘйҖҡиҝҮеҜ»жүҫдёҖдёӘиҰҒд№ҲеұһдәҺSдёӯзҡ„е…ғзҙ жҲ–иҰҒд№ҲдёҚеұһдәҺSдёӯзҡ„е…ғзҙ жқҘзј©еҮҸй—®йўҳ规模гҖӮжҲ‘们е°ҶеңЁеҗҺйқўиҝӣиЎҢиҝҷдёҖж“ҚдҪңгҖӮжҲ‘们е…ҲдҪҝз”Ёз®ҖжҙҒжҳҺдәҶзҡ„еҪ’зәіеҒҮи®ҫпјҡ
еҪ’зәіеҒҮи®ҫпјҡжҲ‘们已з»ҸзҹҘйҒ“еҰӮдҪ•еҺ»и§ЈеҶідёҖдёӘеҗ«n-1дёӘе…ғзҙ йӣҶеҗҲзҡ„й—®йўҳгҖӮ
жңҖеҹәжң¬зҡ„жғ…еҶөеҫҲз®ҖеҚ•пјҡеҰӮжһңйӣҶеҗҲдёӯеҸӘеҗ«жңүдёҖдёӘе…ғзҙ пјҢйӣҶеҗҲеҝ…йЎ»жҳ е°„еҲ°иҮӘиә«пјҢиҝҷе°ұжҳҜдёҖдёӘдёҖдёҖжҳ е°„гҖӮеҒҮи®ҫжҲ‘们已з»ҸжңүдәҶдёҖдёӘеҗ«жңүnдёӘе…ғзҙ зҡ„йӣҶеҗҲAпјҢзҺ°еңЁжҲ‘们еҜ»жүҫдёҖдёӘж»Ўи¶ій—®йўҳжқЎд»¶зҡ„еӯҗйӣҶSгҖӮеҫҲжҳҫ然жүҫеҲ°дёҖдёӘдёҚеұһдәҺSйӣҶеҗҲзҡ„е…ғзҙ иҰҒжҜ”жүҫеҲ°дёҖдёӘеҢ…еҗ«еңЁSйӣҶеҗҲдёӯе…ғзҙ з®ҖеҚ•гҖӮжҲ‘们еҸҜд»Ҙи®Өдёәд»»дҪ•дёҖдёӘе…ғзҙ iеҰӮжһңжІЎжңүиў«е…¶д»–е…ғзҙ жҳ е°„пјҢйӮЈд№ҲiдёҚеҸҜиғҪеҢ…еҗ«еңЁSдёӯгҖӮпјҲжҚўеҸҘиҜқиҜҙпјҢеңЁеӣҫеҸідҫ§зҡ„е…ғзҙ iпјҢеҰӮжһңжІЎжңүдёҖжқЎиҫ№дёҺд№ӢзӣёиҝһпјҢйӮЈд№ҲiдёҚеҸҜиғҪеңЁSдёӯпјүеҗҰеҲҷзҡ„иҜқпјҢеҰӮжһңiвҲҲSпјҢеҒҮи®ҫSдёӯжңүkдёӘе…ғзҙ пјҢйӮЈд№ҲиҝҷkдёӘе…ғзҙ жңҖеӨҡжҳ е°„еҲ°k-1дёӘе…ғзҙ пјҢеӣ жӯӨиҝҷдёӘжҳ е°„дёҚеҸҜиғҪж—¶дёҖдёҖжҳ е°„гҖӮеҰӮжһңеӯҳеңЁиҝҷж ·зҡ„iпјҢжҲ‘们仅йңҖиҰҒжҠҠiд»ҺйӣҶеҗҲдёӯ移йҷӨеҚіеҸҜгҖӮжҲ‘们зҺ°еңЁжңүдёҖдёӘеҗ«жңүn-1дёӘе…ғзҙ дё”и®©еҮҪж•°fжҳ е°„еҲ°иҮӘиә«зҡ„йӣҶеҗҲAвҖҷ=A-{i}гҖӮйҖҡиҝҮеҪ’зәіеҒҮи®ҫжҲ‘们зҹҘйҒ“еҰӮдҪ•еҺ»жұӮи§ЈAвҖҷгҖӮеҰӮжһңдёҚеӯҳеңЁиҝҷж ·зҡ„iпјҢйӮЈд№Ҳжҳ е°„е°ұжҳҜдёҖдёҖжҳ е°„пјҢиҝҷж ·жҲ‘们е°ұи§ЈеҶідәҶй—®йўҳгҖӮ
иҝҷз§Қи§Јжі•зҡ„е…ій”®еңЁдәҺжҲ‘们еҝ…须移йҷӨiгҖӮжҲ‘们еңЁдёҠйқўиҜҒжҳҺдәҶiдёҚеҸҜиғҪеұһдәҺSйӣҶгҖӮиҝҷжҳҜеҪ’зәіжі•зҡ„дјҳеҠҝд№ӢеӨ„гҖӮдёҖж—ҰжҲ‘们移йҷӨдәҶдёҖдёӘе…ғзҙ зј©еҮҸдәҶй—®йўҳзҡ„规模жҲ‘们е°ұз®—е®ҢжҲҗдәҶгҖӮ然иҖҢжҲ‘们еҝ…йЎ»ж јеӨ–е°ҸеҝғпјҢзј©еҮҸеҗҺзҡ„й—®йўҳе’ҢеҺҹй—®йўҳеҮ д№ҺжҳҜдёҖж ·зҡ„гҖӮпјҲйҷӨдәҶ规模еӨ–пјүеҜ№дәҺйӣҶеҗҲAе’ҢеҮҪж•°fзҡ„е”ҜдёҖжқЎд»¶е°ұжҳҜfи®©Aжҳ е°„еҲ°иҮӘиә«гҖӮз”ұдәҺ并没жңүе…ғзҙ жҳ е°„еҲ°iпјҢиҝҷдёӘжқЎд»¶еҜ№дәҺA-{i}еҗҺзҡ„йӣҶеҗҲдҫқ然жҲҗз«ӢгҖӮеҪ“жІЎжңүе…ғзҙ еҸҜд»Ҙ移йҷӨзҡ„ж—¶еҖҷиҝҷдёӘз®—жі•д№ҹе°ұжү§иЎҢз»“жқҹдәҶгҖӮ
е®һзҺ°пјҡдёҠйқўзҡ„з®—жі•жҳҜйҖҡиҝҮдҪҝз”ЁйҖ’еҪ’зҡ„иҝҮзЁӢеҠ д»ҘжҸҸиҝ°зҡ„гҖӮеңЁжҜҸдёҖжӯҘдёӯжҲ‘们жүҫеҲ°дёҖдёӘжІЎжңүе…¶д»–е…ғзҙ жҳ е°„еҲ°е®ғзҡ„е…ғзҙ пјҢ移йҷӨе®ғпјҢ然еҗҺ继з»ӯйҖ’еҪ’жү§иЎҢгҖӮ然иҖҢе®һзҺ°ж–№жі•е№¶дёҚйңҖиҰҒз”ЁйҖ’еҪ’гҖӮжҲ‘们еҸҜд»ҘеҜ№жҜҸдёҖдёӘе…ғзҙ iдҪҝз”ЁдёҖдёӘи®Ўж•°еҷЁc[i]гҖӮеҲқе§Ӣжғ…еҶөдёӢc[i]йңҖиҰҒе’Ңжҳ е°„еҲ°iзҡ„е…ғзҙ ж•°зӣ®зӣёзӯүгҖӮиҝҷеҸҜд»ҘйҖҡиҝҮжү«жҸҸж•°з»„пјҲиҝӣиЎҢnжӯҘпјүд»ҘеҸҠеўһеҠ еҜ№еә”зҡ„и®Ўж•°еҷЁеҖјиҖҢи®Ўз®—еҮәжқҘгҖӮ然еҗҺжҲ‘们жҠҠжүҖжңүи®Ўж•°еҖјдёә0зҡ„е…ғзҙ ж”ҫеңЁдёҖдёӘйҳҹеҲ—дёӯгҖӮеңЁжҜҸдёҖжӯҘжү§иЎҢдёӯпјҢжҲ‘们移йҷӨйҳҹеҲ—дёӯзҡ„е…ғзҙ jпјҲеҗҢж—¶д№ҹ移йҷӨйӣҶеҗҲдёӯзҡ„еҜ№еә”еҖјпјүгҖӮеҮҸе°Ҹc[f(j)]зҡ„еҖјпјҢеҰӮжһңc[f(j)]=0пјҢжҲ‘们е°ұжҠҠf(j)ж”ҫеңЁйҳҹеҲ—дёӯгҖӮеҪ“йҳҹеҲ—дёәз©әж—¶з®—жі•жү§иЎҢз»“жқҹгҖӮз®—жі•жҸҸиҝ°еҰӮдёӢпјҡ
жҳ е°„з®—жі•пјҲf:ж•ҙеһӢж•°з»„[1..n]пјү
begin
S:=A{AжҳҜд»Һ1еҲ°nзҡ„ж•°еӯ—жһ„жҲҗзҡ„ж•°з»„}
for j:=1 to n do c[j]:=0;
for j:=1 to n do increament(c[f(j)]);
for j:=1 to n do
if c[j]=0 then put j in Queue;
while Queue is not empty do
remove i from the top of the queue;
S:=S-{i};
decrement c[f(i)];
if c[f(i)]=0 then put f(i) in Queue
end;
еӨҚжқӮеәҰпјҡеҲқе§ӢеҢ–йғЁеҲҶйңҖиҰҒO(n)зҡ„ж“ҚдҪңж—¶й—ҙпјҢжҜҸдёҖдёӘе…ғзҙ жңҖеӨҡжңүдёҖж¬Ўжңәдјҡиў«ж”ҫзҪ®еҲ°йҳҹеҲ—дёӯпјҢжҠҠе…ғзҙ д»ҺйҳҹеҲ—дёӯ移йҷӨеҸӘйңҖиҰҒеёёж•°ж—¶й—ҙгҖӮжӯҘйӘӨзҡ„жҖ»ж•°O(n)гҖӮ
жҖ»з»“пјҡеңЁжң¬дҫӢдёӯеҮҸе°‘й—®йўҳзҡ„规模主иҰҒеңЁд»ҺйӣҶеҗҲдёӯеҲ йҷӨе…ғзҙ дёҠгҖӮеӣ жӯӨжҲ‘们иҜ•еӣҫеңЁдёҚж”№еҸҳй—®йўҳжқЎд»¶зҡ„жғ…еҶөдёӢеҜ»жүҫдёҖз§ҚжңҖз®ҖеҚ•зҡ„ж–№жі•жқҘ移йҷӨе…ғзҙ гҖӮз”ұдәҺеҜ№дәҺеҮҪж•°зҡ„е”ҜдёҖзҡ„иҰҒжұӮжҳҜе®ғеҝ…йЎ»жҠҠAжҳ е°„еҲ°иҮӘиә«пјҢж•…жҲ‘们дјҡеҫҲиҮӘ然ең°йҖүжӢ©дёҖдёӘжІЎжңүе…¶д»–е…ғзҙ жҳ е°„еҲ°зҡ„е…ғзҙ гҖӮ
жЈҖжҹҘзәҝж®өзҡ„еҢ…еҗ«жғ…еҶөгҖҗQ3гҖ‘
й—®йўҳпјҡиҫ“е…ҘжҳҜдёҖжқЎзәҝдёҠдёҖзі»еҲ—й—ҙж–ӯзәҝж®өзҡ„йӣҶеҗҲI1,I2вҖҰInгҖӮеҜ№дәҺжҜҸдёҖдёӘзәҝж®өIjйғҪз»ҷеҮәдәҶе®ғзҡ„дёӨдёӘз«ҜзӮ№LjпјҲе·Ұз«ҜзӮ№пјү,RjпјҲеҸіз«ҜзӮ№пјүгҖӮжҲ‘们жғіж Үи®°еҮәжүҖжңүеҢ…еҗ«еңЁе…¶д»–зәҝж®өдёӯзҡ„зәҝж®өгҖӮжҚўеҸҘиҜқиҜҙпјҢдёҖдёӘзәҝж®өIjеҝ…йЎ»иў«ж Үи®°еҮәжқҘпјҢеҰӮжһңеӯҳеңЁеҸҰдёҖжқЎзәҝж®өIk(kвү j)并且满足LkвүӨLjд»ҘеҸҠRkвүҘRjгҖӮдёәдәҶз®ҖеҢ–иө·и§ҒжҲ‘们еҒҮе®ҡжүҖжңүзҡ„зәҝж®өйғҪжҳҜдёҚдёҖж ·зҡ„пјҲдҫӢеҰӮд»»ж„ҸдёӨдёӘзәҝж®өйғҪдёҚеҸҜиғҪеҗҢж—¶е…·жңүзӣёеҗҢзҡ„е·Ұз«ҜзӮ№е’ҢеҸіз«ҜзӮ№пјҢдҪҶжҳҜе®ғ们еҸҜиғҪжңүдёӨдёӘз«ҜзӮ№дёӯзҡ„жҹҗдёҖдёӘзӣёеҗҢпјүгҖӮеӣҫ2еұ•зӨәдәҶиҝҷж ·зҡ„дёҖдёӘзәҝж®өйӣҶеҗҲгҖӮпјҲдёәдәҶжӣҙеҘҪзҡ„еұ•зӨәпјҢжҜҸдёҖжқЎзәҝж®өйғҪж”ҫеңЁеҸҰдёҖжқЎзәҝж®өдёҠйқўиҖҢдёҚжҳҜж”ҫеңЁдёҖжқЎзәҝдёҠпјү

з”Ёзӣҙи§Ӯзҡ„ж–№жі•дҪҝз”ЁеҪ’зәіжі•дё»иҰҒжҳҜ移йҷӨдёҖдёӘзәҝж®өIпјҢеҜ№дәҺеү©дёӢзҡ„зәҝж®өдҪҝз”ЁйҖ’еҪ’зҡ„ж–№жі•еҠ д»Ҙи§ЈеҶіпјҢ然еҗҺеңЁжЈҖжҹҘжҠҠIж”ҫеӣһеҗҺзҡ„ж•ҲжһңгҖӮй—®йўҳеңЁдәҺжҠҠзәҝж®өIж”ҫеӣһйңҖиҰҒжЈҖжҹҘжүҖжңүе…¶д»–зҡ„зәҝж®өжқҘеҲӨж–ӯ他们дёӯжҳҜеҗҰеҢ…еҗ«IжҲ–иҖ…иў«IжүҖеҢ…еҗ«гҖӮиҝҷйңҖиҰҒжЈҖжҹҘIе’Ңе…¶дҪҷn-1жқЎзәҝж®өпјҢз®—жі•дёӯдҪҝз”Ёзҡ„жҜ”иҫғе°ҶиҫҫеҲ°n-1+n-2+вҖҰ+1=n(n-1)/2ж¬ЎгҖӮдёәдәҶиҺ·еҫ—дёҖдёӘжӣҙеҘҪзҡ„з®—жі•жҲ‘们йңҖиҰҒеҒҡдёӨ件дәӢпјҡйҰ–е…ҲжҲ‘们йҖүжӢ©дёҖжқЎзү№ж®Ҡзҡ„зәҝж®өеҠ д»Ҙ移йҷӨпјҢе…¶ж¬ЎжҲ‘们е°ҪеҸҜиғҪеӨҡзҡ„дҪҝз”Ёд»Һжӣҙе°Ҹ规模问йўҳзҡ„и§ЈеҶіж–№жЎҲдёӯ收йӣҶеҲ°зҡ„дҝЎжҒҜгҖӮ
йҖүе®ҡIдёәжүҖжңүзәҝж®өдёӯе…·жңүжңҖеӨ§е·Ұз«ҜзӮ№еҖјзҡ„зәҝж®өпјҢз”ұдәҺе…¶д»–зәҝж®өе·Ұз«ҜзӮ№еҖјйғҪиҫғд№Ӣе°ҸпјҢиҝҷж ·е°ұдёҚйңҖиҰҒеҶҚжЈҖжҹҘе·Ұз«ҜзӮ№еҖјдәҶгҖӮеӣ жӯӨпјҢдёәдәҶиҰҒжЈҖжҹҘIжҳҜеҗҰеҢ…еҗ«дәҺе…¶д»–зәҝж®өд№ӢдёӯпјҢжҲ‘们еҸӘйңҖиҰҒжЈҖжҹҘе…¶д»–зәҝж®өдёӯжҳҜеҗҰжңүеҸіз«ҜзӮ№еҖјжҜ”IеҸіз«ҜзӮ№еҖјжӣҙеӨ§зҡ„зәҝж®өгҖӮдёәдәҶжүҫеҲ°иҝҷд№ҲдёҖжқЎе…·жңүжңҖеӨ§е·Ұз«ҜзӮ№еҖјзҡ„зәҝж®өжҲ‘们еҸҜд»ҘдҫқжҚ®зәҝж®өзҡ„е·Ұз«ҜзӮ№еҖјеҜ№жүҖжңүзәҝж®өиҝӣиЎҢжҺ’еәҸ并且жҢүз…§ж¬ЎеәҸеҜ№е…¶иҝӣиЎҢжҗңзҙўгҖӮеҒҮе®ҡзәҝж®өе·Із»ҸжҢүз…§ж¬ЎеәҸжҺ’еҘҪпјҢL1вүӨL2вүӨвҖҰвүӨLnгҖӮеҪ’зәіеҒҮи®ҫеҰӮдёӢпјҡ
еҪ’зәіеҒҮи®ҫпјҡжҲ‘们已з»ҸзҹҘйҒ“еҰӮдҪ•еҺ»и§ЈеҶіеҢ…еҗ«I1,I2вҖҰIn-1жқЎзәҝж®өзҡ„й—®йўҳгҖӮ
жңҖеҹәжң¬зҡ„й—®йўҳеҫҲз®ҖеҚ•пјҢеҰӮжһңеҸӘжңүдёҖжқЎзәҝж®өпјҢйӮЈд№Ҳе®ғиӮҜе®ҡдёҚдјҡиў«ж Үи®°гҖӮзҺ°еңЁжҲ‘们жқҘиҖғиҷ‘InгҖӮйҖҡиҝҮеҪ’зәіеҒҮи®ҫжҲ‘们зҹҘйҒ“е·Із»ҸзЎ®е®ҡдәҶеңЁзәҝж®өI1еҲ°In-1дёӯжңүе“Әдәӣзәҝж®өжҳҜеҢ…еҗ«еңЁе…¶д»–зәҝж®өд№Ӣдёӯзҡ„пјҢжҲ‘们йңҖиҰҒзЎ®е®ҡInжҳҜеҗҰеҢ…еҗ«е…¶д»–пјҲд№ӢеүҚжІЎжңүиў«ж Үи®°иҝҮпјүзҡ„зәҝж®өпјҢд»ҘеҸҠInжҳҜеҗҰиў«еҢ…еҗ«еңЁе…¶д»–зәҝж®өд№ӢдёӯгҖӮи®©жҲ‘们йҰ–е…ҲжқҘжЈҖжҹҘInжҳҜеҗҰиў«еҢ…еҗ«еңЁе…¶д»–зәҝж®өд№ӢдёӯгҖӮеҰӮжһңInиў«еҢ…еҗ«еңЁдёҖжқЎзәҝж®өдёӯпјҢеҒҮеҰӮжҳҜIj,j<nпјҢдәҺжҳҜRjвүҘRnгҖӮиҝҷжҳҜе”ҜдёҖзҡ„еҝ…иҰҒжқЎд»¶пјҲеӣ дёәжҺ’еәҸе·Із»ҸзЎ®дҝқдәҶLjвүӨLnпјүгҖӮеӣ жӯӨжҲ‘们еҸӘйңҖиҰҒеңЁд№ӢеүҚзҡ„зәҝж®өдёӯи®°еҪ•жӢҘжңүзҡ„жңҖеӨ§еҸіз«ҜзӮ№еҖјеҚіеҸҜгҖӮжҠҠиҜҘеҸіз«ҜзӮ№еҖјдёҺRnиҝӣиЎҢжҜ”иҫғе°ұиғҪз»ҷеҮәжҲ‘们зӯ”жЎҲгҖӮжҲ‘们зЁҚеҫ®ж”№еҸҳдёҖдёӢеҪ’зәіеҒҮи®ҫпјҡ
жӣҙејәзҡ„еҪ’зәіеҒҮи®ҫпјҡжҲ‘们已з»ҸзҹҘйҒ“еҰӮдҪ•и§ЈеҶіI1,I2вҖҰIn-1зҡ„й—®йўҳпјҢеҗҢж—¶д№ҹжүҫеҮәдәҶ他们дёӯеҸіз«ҜзӮ№зҡ„жңҖеӨ§еҖјгҖӮ
жҲ‘们еҶҚдёҖж¬Ўи®©InдҪңдёәжӢҘжңүжңҖеӨ§е·Ұз«ҜзӮ№еҖјзҡ„зәҝж®өпјҢ然еҗҺи®©MaxRдҪңдёәеүҚn-1жқЎзәҝж®өдёӯеҸіз«ҜзӮ№зҡ„жңҖеӨ§еҖјгҖӮеҰӮжһңMaxRвүҘRnпјҢйӮЈд№ҲInе°ұеә”иҜҘиў«ж Үи®°пјҢеҗҰеҲҷ(MaxRвүӨRn)Rnе°ұжҲҗдёәж–°зҡ„жңҖеӨ§зҡ„жңҖеӨ§еҖјгҖӮпјҲиҝҷжңҖеҗҺдёҖжӯҘжҳҜеҝ…иҰҒзҡ„пјҢеӣ дёәжҲ‘们зҺ°еңЁдёҚд»…д»…жҳҜж Үи®°зәҝж®өпјҢеҗҢж—¶жҲ‘们д№ҹеңЁеҜ»жүҫжңҖеӨ§зҡ„еҸіз«ҜзӮ№еҖјгҖӮпјүжҲ‘们зҺ°еңЁд»…йҖҡиҝҮдёҖжӯҘжЈҖжҹҘе°ұиғҪзЎ®е®ҡInзҡ„зҠ¶жҖҒгҖӮ
дёәдәҶе®ҢжҲҗиҝҷдёӘз®—жі•жҲ‘们йңҖиҰҒжЈҖжҹҘInжҳҜеҗҰеҢ…еҗ«дёҖжқЎд№ӢеүҚжңӘиў«ж Үи®°иҝҮзҡ„зәҝж®өгҖӮInеҢ…еҗ«дёҖжқЎзәҝж®өIj,j<nпјҢеҸӘжңүеҪ“ж»Ўи¶іжқЎд»¶Lj=Lnдё”Rj<Rnж—¶жүҚиЎҢгҖӮжҲ‘们еҸҜд»ҘйҖҡиҝҮеўһејәжҺ’еәҸеҠҹиғҪжқҘеӨ„зҗҶиҝҷз§Қжғ…еҶөгҖӮзҺ°еңЁжҲ‘们дёҚд»…жҢүз…§е·Ұз«ҜзӮ№еҖјиҝӣиЎҢжҺ’еәҸпјҢеҗҢж—¶еҜ№дәҺе…·жңүзӣёеҗҢе·Ұз«ҜзӮ№еҖјзҡ„зәҝж®өпјҢжҲ‘们дҫқжҚ®д»–们зҡ„еҸіз«ҜзӮ№еҖјзҡ„йҖҶеәҸжқҘиҝӣиЎҢжҺ’еәҸгҖӮиҝҷж ·иғҪеӨҹжҺ’йҷӨдёҠйқўжҸҗеҲ°зҡ„жғ…еҶөеҮәзҺ°пјҢеӣ дёәIjе°Ҷдјҡж”ҫзҪ®еңЁInд№ӢеҗҺпјҲеҸіз«ҜзӮ№еҖјиҫғе°ҸпјүпјҢиҖҢдё”Ijзҡ„еҢ…еҗ«жҖ§е°Ҷдјҡиў«дёҠдёҖдёӘз®—жі•жүҫеҲ°гҖӮе®Ңж•ҙзҡ„з®—жі•еҰӮдёӢжүҖзӨәпјҡ
зәҝж®өеҢ…еҗ«жҖ§з®—жі•
(I1,I2,вҖҰIn:зәҝж®ө)
{з”ЁдёҖеҜ№Lj,RjжқҘз»ҷеҮәдёҖжқЎзәҝж®өIj}
{жҲ‘们еҒҮе®ҡжІЎжңүдёӨжқЎзәҝж®өжҳҜе®Ңе…ЁдёҖж ·зҡ„}
{еҪ“Ijиў«еҢ…еҗ«еңЁеҸҰдёҖжқЎзәҝж®өдёӯж—¶пјҢMark[j]е°Ҷдјҡиў«ж Үи®°дёәзңҹ}
begin
жҢүз…§зәҝж®өзҡ„е·Ұз«ҜзӮ№еҖјйҖ’еўһж¬ЎеәҸеҜ№жүҖжңүзәҝж®өиҝӣиЎҢжҺ’еәҸ
е…·жңүзӣёеҗҢе·Ұз«ҜзӮ№еҖјзҡ„зәҝж®өжҢү照他们еҸіз«ҜзӮ№еҖјйҖ’еҮҸзҡ„ж¬ЎеәҸиҝӣиЎҢжҺ’еәҸ
{for all j<k either Lj<Lk or Lj=Lk and Rj>Rk}
MaxR:=R1;
for j:=2 to n do
if RjвүӨMaxR then
Mark[j]:=true;
else
Mark[j]:=false;
MaxR:=Rj;
end;
еӨҚжқӮеәҰпјҡйҷӨдәҶжҺ’еәҸеӨ–пјҢиҝҷдёӘз®—жі•еҢ…еҗ«дёҖдёӘж¶үеҸҠеҲ°O(n)жӯҘж“ҚдҪңзҡ„еҫӘзҺҜгҖӮз”ұдәҺжҺ’еәҸйңҖиҰҒO(nlogn)жӯҘж“ҚдҪңпјҢж•…е…¶еҚ жҚ®дәҶз®—жі•дё»иҰҒзҡ„иҝҗиЎҢж—¶й—ҙгҖӮ
жҖ»з»“пјҡиҝҷдёӘдҫӢеӯҗйҳҗжҳҺдәҶдёҖдёӘдёҚжҳҜйӮЈд№ҲзӣҙжҺҘиҝҗз”ЁеҪ’зәіжі•зҡ„ж–№жі•гҖӮйҰ–е…ҲжҲ‘们йҖүжӢ©еҸҜд»Ҙиҝҗз”ЁеҪ’зәіжі•жү§иЎҢзҡ„еәҸеҲ—гҖӮ然еҗҺжҲ‘们и®ҫи®ЎеҪ’зәіеҒҮи®ҫпјҢиҜҘеҒҮи®ҫиғҪеӨҹжҡ—зӨәеҮәжңҹжңӣзҡ„з»“жһңеҗҢж—¶е®ғд№ҹжҳ“жӢ“еұ•гҖӮйҮҚзӮ№ж”ҫеңЁиҝҷдәӣжӯҘйӘӨдёҠе°ұиғҪи®©еҜ№еҫҲеӨҡз®—жі•зҡ„и®ҫи®ЎеҸҳеҫ—з®ҖеҚ•гҖӮ
жҳҺжҷәзҡ„йҖүжӢ©еҪ’зәіеәҸеҲ—
еңЁеүҚйқўзҡ„дҫӢеӯҗдёӯпјҢйҮҚзӮ№йғҪж”ҫеңЁеҜ»жүҫдёҖдёӘзј©еҮҸй—®йўҳ规模зҡ„з®—жі•дёҠгҖӮиҝҷжҳҜдҪҝз”ЁеҪ’зәіжі•зҡ„жң¬иҙЁгҖӮ然иҖҢжңүеҫҲеӨҡж–№жі•д№ҹиғҪе®һзҺ°иҝҷдёҖзӮ№гҖӮйҰ–е…ҲпјҢй—®йўҳеҸҜиғҪеҢ…еҗ«дёҖдәӣеҸӮж•°пјҲдҫӢеҰӮеӣҫдёӯзҡ„е·Ұз«ҜзӮ№еҸіз«ҜзӮ№пјҢйЎ¶зӮ№е’Ңиҫ№пјүпјҢжҲ‘们еҝ…йЎ»еҶіе®ҡеҜ№е…¶дёӯе“ӘдёҖдёӘеҸӮж•°иҝӣиЎҢзј©еҮҸгҖӮе…¶ж¬ЎпјҢжҲ‘们еҸҜиғҪиғҪеӨҹжҺ’йҷӨжҺүи®ёеӨҡеҸҜиғҪе…ғзҙ пјҢдҪҶжҲ‘们жғійҖүжӢ©е…¶дёӯжңҖе®№жҳ“зҡ„дёҖдёӘгҖӮпјҲдҫӢеҰӮжңҖе·Ұиҫ№зҡ„з«ҜзӮ№пјҢжңҖе°Ҹзҡ„ж•°еӯ—пјү第дёүпјҢжҲ‘们еҸҜиғҪжғіеҜ№й—®йўҳеҠ ејәйҷҗеҲ¶жқЎд»¶пјҲдҫӢеҰӮзәҝж®өжҳҜжңүеәҸжҺ’еҲ—зҡ„пјүгҖӮеҪ“然иҝҳжңүе…¶д»–еҫҲеӨҡеҸҳеҢ–гҖӮдҫӢеҰӮжҲ‘们еҸҜд»ҘеҒҮи®ҫжҲ‘们已з»ҸзҹҘйҒ“еҜ№дёҖдәӣе°ҸдәҺnзҡ„еҖјзҡ„й—®йўҳеҰӮдҪ•и§ЈеҶіиҖҢдёҚжҳҜд»…д»…зҡ„n-1гҖӮиҝҷеҫҖеҫҖжҳҜдёҖдёӘжңүж•Ҳзҡ„еҒҮи®ҫгҖӮд»»дҪ•зј©еҮҸй—®йўҳ规模зҡ„еҒҡжі•йғҪжҳҜеҖјеҫ—иҖғиҷ‘зҡ„пјҢеӣ дёәиҝҷз§ҚеҒҡжі•иғҪеӨҹеј•еҜјжҲ‘们еӣһеҲ°й—®йўҳзҡ„жңҖеҹәжң¬жғ…еҶөпјҢиҖҢиҝҷж—¶еҫҖеҫҖжҲ‘们иғҪеӨҹзӣҙжҺҘи§ЈеҶігҖӮеӣһеҲ°еңЁеҪ’зәіжі•дёӯи®Ёи®әзҡ„жҺ’еәҸдҫӢеӯҗпјҢжҲ‘们еҸҜд»ҘжҠҠеҜ№nдёӘе…ғзҙ зҡ„жҺ’еәҸзј©еҮҸдёәеҜ№дёӨдёӘеҗ„еҗ«n/2дёӘе…ғзҙ зҡ„еӯҗйӣҶзҡ„жҺ’еәҸгҖӮ然еҗҺеҸҜд»ҘеҜ№иҝҷдёӨдёӘжҺ’еҘҪеәҸзҡ„йӣҶеҗҲиҝӣиЎҢеҗҲ并пјҲеј•еҮәдёҖдёӘз§°дёәеҪ’并жҺ’еәҸзҡ„з®—жі•пјүгҖӮжҠҠй—®йўҳеҲҶи§ЈпјҲеҪ’зәіжҖ§зҡ„пјүдёәдёҖдәӣзӣёеҗҢзҡ„йғЁеҲҶжҳҜдёҖдёӘеҫҲжңүз”Ёзҡ„жҠҖе·§пјҲжҲ‘们е°ҶдјҡеңЁеҗҺйқўиҝӣиЎҢи®Ёи®әпјүпјҢиҜҘжҠҖе·§з§°дёәеҲҶжІ»гҖӮ
дёҖдәӣй—®йўҳзҡ„зј©еҮҸеҫҲе®№жҳ“е°ұиғҪе®һзҺ°пјҢ然иҖҢдёҖдәӣеҚҙеҫҲйҡҫе®һзҺ°гҖӮдёҖдәӣ规模зҡ„зј©еҮҸиғҪеӨҹеёҰжқҘеҫҲдёҚй”ҷзҡ„з®—жі•пјҢ然иҖҢдёҖдәӣеҚҙдёҚиЎҢгҖӮеңЁеҫҲеӨҡжғ…еҶөдёӢиҝҷе°ұжҳҜй—®йўҳдёӯе”ҜдёҖзҡ„еӣ°йҡҫд№ӢеӨ„пјҢдёҖж—ҰеҒҡеҮәдәҶжӯЈзЎ®зҡ„йҖүжӢ©йӮЈд№Ҳеү©дёӢзҡ„е°ұеҫҲе®№жҳ“дәҶпјҲдҫӢеҰӮеңЁжҳ е°„й—®йўҳдёӯе…ғзҙ iзҡ„йҖүжӢ©йӮЈж ·пјүгҖӮиҝҷеңЁж•°еӯҰдёӯжһҒе…¶йҮҚиҰҒгҖӮжІЎжңүдәәиғҪеӨҹдёҚйҖҡиҝҮйҰ–е…ҲжҖқиҖғеҰӮдҪ•йҖүжӢ©дёҖдёӘеҪ’зәіеәҸеҲ—е°ұзӣҙжҺҘи·іеҲ°еҪ’зәіиҜҒжҳҺдёӯеҺ»гҖӮжӯЈеҰӮдј°и®Ўзҡ„йӮЈж ·пјҢиҝҷеңЁз®—жі•и®ҫи®Ўдёӯд№ҹжҳҜеҫҲйҮҚиҰҒзҡ„гҖӮеңЁиҝҷдёҖйғЁеҲҶжҲ‘们е°Ҷз»ҷеҮәдёӨдёӘдҫӢеӯҗпјҢеңЁиҝҷдёӨдёӘдҫӢеӯҗдёӯпјҢзј©еҮҸеәҸеҲ—зҡ„йҮҚиҰҒжҖ§еҫ—еҲ°дәҶдҪ“зҺ°гҖӮзү№еҲ«жҳҜеҗҚдәәзҡ„дҫӢеӯҗпјҢе®ғиҜҙжҳҺдәҶдёҖз§ҚдёҚеҗҢдәҺдёҖиҲ¬зҡ„йЎәеәҸгҖӮ
жӢ“жү‘жҺ’еәҸгҖҗQ4гҖ‘
еҒҮи®ҫиҝҷйҮҢжңүдёҖзі»еҲ—зҡ„д»»еҠЎпјҢиҝҷдәӣд»»еҠЎжҜҸж¬ЎеҸӘиғҪжү§иЎҢе…¶дёӯдёҖдёӘгҖӮе…¶дёӯжңүдёҖдәӣд»»еҠЎиҰҒдҫқиө–е…¶д»–д»»еҠЎзҡ„е®ҢжҲҗпјҢеҰӮжһңе…¶д»–д»»еҠЎжІЎжңүе®ҢжҲҗеҲҷиҝҷдәӣд»»еҠЎдёҚеҸҜиғҪејҖе§Ӣжү§иЎҢгҖӮе·ІзҹҘжүҖжңүзҡ„дҫқиө–е…ізі»пјҢжҲ‘们жғіжүҫеҲ°дёҖдёӘз¬ҰеҗҲдҫқиө–е…ізі»зҡ„д»»еҠЎе®үжҺ’и®ЎеҲ’иЎЁгҖӮпјҲеҚіжҜҸдёҖдёӘиў«и®ЎеҲ’жү§иЎҢзҡ„д»»еҠЎеҸӘжңүеңЁе®ғдҫқиө–зҡ„д»»еҠЎе…ЁйғЁе®ҢжҲҗж—¶жүҚеҸҜд»ҘејҖе§Ӣжү§иЎҢпјүжҲ‘们жғіиҰҒи®ҫи®ЎдёҖз§ҚиғҪеӨҹиҝ…йҖҹдә§з”ҹеҮәиҝҷд№ҲдёҖдёӘи®ЎеҲ’иЎЁзҡ„з®—жі•гҖӮиҜҘй—®йўҳд№ҹе°ұжҳҜжӢ“жү‘жҺ’еәҸгҖӮд»»еҠЎе’Ң他们зҡ„дҫқиө–е…ізі»иғҪеӨҹйҖҡиҝҮдёҖе№…жңүеҗ‘еӣҫеҫ—еҲ°еұ•зҺ°гҖӮдёҖдёӘжңүеҗ‘еӣҫжӢҘжңүдёҖдёӘйЎ¶зӮ№зҡ„йӣҶеҗҲVпјҲдёҺдҫӢеӯҗдёӯзҡ„д»»еҠЎзӣёеҜ№еә”пјүпјҢд»ҘеҸҠдёҖдёӘз”ұдёҖеҜ№йЎ¶зӮ№жһ„жҲҗзҡ„иҫ№зҡ„йӣҶеҗҲEгҖӮеҰӮжһңдёҖдёӘдёҺvеҜ№еә”зҡ„д»»еҠЎеҝ…йЎ»еңЁдёҖдёӘдёҺwеҜ№еә”зҡ„д»»еҠЎд№ӢеүҚжү§иЎҢпјҢйӮЈд№Ҳеӣҫдёӯе°ұеӯҳеңЁдёҖжқЎд»ҺvеҲ°wзҡ„иҫ№(иЎЁзӨә(v,w)вҲҲE)гҖӮиҜҘеӣҫдёҖе®ҡдёәж— зҺҜеӣҫпјҢеҗҰеҲҷзҺҜдёҠзҡ„д»»еҠЎе°Ҷж°ёиҝңдёҚеҸҜиғҪејҖе§Ӣжү§иЎҢгҖӮиҝҷйҮҢз»ҷеҮәдәҶдҪҝз”ЁеӣҫжқҘиҜҙжҳҺй—®йўҳзҡ„з®ҖеҚ•жҸҸиҝ°гҖӮ
й—®йўҳпјҡз»ҷе®ҡдёҖдёӘжңүnдёӘйЎ¶зӮ№зҡ„жңүеҗ‘ж— зҺҜеӣҫG=(V,E)пјҢиҝҷдәӣйЎ¶зӮ№д»Һ1еҲ°nиҝӣиЎҢзј–еҸ·пјҢеӣ жӯӨеҰӮжһңйЎ¶зӮ№vиў«ж Үи®°дёәkпјҢйӮЈд№ҲйЎ¶зӮ№vеҸҜд»ҘйҖҡиҝҮдёҖжқЎзӣҙжҺҘи·Ҝеҫ„еҲ°иҫҫжүҖжңүзј–еҸ·еӨ§дәҺkзҡ„йЎ¶зӮ№гҖӮпјҲдёҖжқЎи·Ҝеҫ„жҳҜдёҖзі»еҲ—зӮ№зҡ„еәҸеҲ—пјҢиҝҷдәӣзӮ№v1,v2вҖҰvkйҖҡиҝҮиҫ№(v1,v2),(v2,v3)вҖҰ(vk-1,vk)зӣёиҝһпјү
жҲ‘们еҶҚдёҖж¬Ўе°қиҜ•дҫқжҚ®и§„жЁЎжӣҙе°Ҹзҡ„й—®йўҳжқҘи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮиҖғиҷ‘дёҖдёӘжӣҙе°Ҹй—®йўҳзҡ„зӣҙжҺҘеҒҡжі•жҳҜ移еҺ»дёҖдёӘйЎ¶зӮ№гҖӮжҚўеҸҘиҜқиҜҙпјҢйҖҡиҝҮдёӢйқўзҡ„ж–№жі•еҸҜд»ҘзңӢеҲ°еҪ’зәіжі•и•ҙеҗ«еңЁйЎ¶зӮ№зҡ„ж•°йҮҸд№ӢдёӯгҖӮ
еҪ’зәіеҒҮи®ҫ1пјҡжҲ‘们已з»ҸзҹҘйҒ“еҰӮдҪ•жҢүз…§дёҠйқўжҸҸиҝ°зҡ„жқЎд»¶з”Ёn-1дёӘйЎ¶зӮ№дёәжүҖжңүзҡ„еӣҫеҒҡдёҠж Үи®°гҖӮ
еҸӘжңүдёҖдёӘйЎ¶зӮ№зҡ„жңҖеҹәжң¬зҡ„жғ…еҶөжҳҜеҫҲз®ҖеҚ•зҡ„гҖӮеҰӮжһңn>1пјҢжҲ‘们еҸҜд»Ҙ移еҺ»дёҖдёӘйЎ¶зӮ№пјҢ然еҗҺе°қиҜ•дҪҝз”ЁеҪ’зәіеҒҮи®ҫпјҢеҶҚе°қиҜ•еҺ»жӢ“еұ•ж Үи®°гҖӮжҲ‘们йҰ–е…ҲйңҖиҰҒж ёе®һзҡ„дёҖзӮ№жҳҜ移йҷӨдёҖдёӘйЎ¶зӮ№еҗҺзҡ„й—®йўҳе’ҢеҺҹжқҘзҡ„й—®йўҳжҳҜдёҖж ·зҡ„пјҲйҷӨдәҶжӣҙе°Ҹзҡ„规模еӨ–пјүгҖӮжӢҘжңүдёҖдёӘдёҖж ·зҡ„й—®йўҳеҫҲеҝ…иҰҒпјҢеҗҰеҲҷеҪ’зәіеҒҮи®ҫе°Ҷж— жі•дҪҝз”ЁгҖӮдҫӢеӯҗдёӯе”ҜдёҖеҒҮи®ҫжҳҜеӣҫдёҚжҳҜеҫӘзҺҜеӣҫгҖӮз”ұдәҺ移йҷӨдёҖдёӘйЎ¶зӮ№дёҚеҸҜиғҪдә§з”ҹдёҖдёӘеҫӘзҺҜеӣҫпјҢйӮЈд№Ҳиҝҷз§Қзј©еҮҸжҳҜеҸҜиЎҢзҡ„гҖӮ
иҝҷз§Қзј©еҮҸзҡ„й—®йўҳеңЁдәҺе°Ҫз®ЎеҒҮи®ҫеҸҜд»ҘдҪҝз”ЁдҪҶжҲ‘жҲ‘们дёҚжё…жҘҡеҰӮдҪ•еҺ»жӢ“еұ•и§ЈеҶіж–№жі•пјҢеҚіжҖҺд№ҲеҺ»ж Ү记移йҷӨзҡ„йЎ¶зӮ№гҖӮжҲ‘们解еҶіиҜҘй—®йўҳзҡ„ж–№жЎҲжҳҜзІҫеҝғйҖүжӢ©йЎ¶зӮ№vгҖӮз”ұдәҺ移еҺ»д»»дҪ•дёҖдёӘйЎ¶зӮ№дә§з”ҹзҡ„规模жӣҙе°Ҹзҡ„й—®йўҳйғҪжҳҜз¬ҰеҗҲиҰҒжұӮзҡ„пјҢжүҖд»ҘжҲ‘们еҸҜд»Ҙд»»ж„ҸйҖүжӢ©дёҖдёӘйЎ¶зӮ№дҪңдёә第nдёӘйЎ¶зӮ№гҖӮеӣ жӯӨпјҢжҲ‘们еә”иҜҘ移йҷӨйӮЈдәӣжңҖе®№жҳ“иҺ·еҸ–ж Үи®°зҡ„зӮ№гҖӮдёҖдёӘжҳҺжҳҫзҡ„йҖүжӢ©жҳҜйӮЈдәӣжІЎжңүдҫқиө–е…ізі»зҡ„йЎ¶зӮ№пјҲд»»еҠЎпјүпјҢд№ҹе°ұжҳҜиҜҘйЎ¶зӮ№зҡ„е…ҘеәҰпјҲжҢҮеҗ‘иҜҘзӮ№зҡ„иҫ№ж•°пјүдёә0гҖӮеҸҜд»ҘжҠҠиҜҘйЎ¶зӮ№ж Үи®°дёә1пјҢиҝҷдёҚдјҡеёҰжқҘд»Җд№Ҳй”ҷиҜҜгҖӮ
дҪҶжҳҜпјҢжҲ‘们жҖ»иғҪжүҫеҲ°дёҖдёӘе…ҘеәҰдёә0зҡ„зӮ№д№Ҳпјҹзӯ”жЎҲжҢүзӣҙи§үжҳҜиӮҜе®ҡзҡ„пјҢдҪҶжҲ‘们еҝ…йЎ»д»ҺжҹҗдёӘең°ж–№ејҖе§ӢгҖӮжҜ«ж— з–‘й—®зҡ„жҳҜпјҢеҰӮжһңжүҖжңүзҡ„йЎ¶зӮ№йғҪжңүеӨ§дәҺ0зҡ„е…ҘеәҰжҲ‘们еҸҜд»Ҙз”Ёеҗ„з§Қж–№ејҸйҒҚеҺҶеӣҫиҖҢдё”ж°ёиҝңдёҚдјҡеҒңжӯўгҖӮдҪҶжҳҜз”ұдәҺеҸӘжңүжңүйҷҗж•°йҮҸзҡ„йЎ¶зӮ№йңҖиҰҒжҲ‘们еҺ»еҫӘзҺҜжҹҘжүҫпјҢиҝҷдёҺжҲ‘们зҡ„еҒҮи®ҫжҳҜзӣёзҹӣзӣҫзҡ„гҖӮпјҲеҗҢзҗҶжҲ‘们д№ҹеҸҜд»Ҙд»ҺеҮәеәҰдёә0зҡ„йЎ¶зӮ№ејҖе§ӢеҜ»жүҫпјҢ然еҗҺжҠҠиҜҘйЎ¶зӮ№ж Үи®°дёәnпјүеү©дёӢзҡ„з®—жі•е°ұеҫҲжё…жҷ°дәҶгҖӮ移йҷӨйҖүжӢ©зҡ„йЎ¶зӮ№зҡ„зӣёйӮ»иҫ№пјҢеү©дёӢзҡ„еӣҫдҫқ然жҳҜж— зҺҜеӣҫпјҢеҶҚз”Ё2еҲ°nж Үи®°еӣҫзҡ„еү©дҪҷйғЁеҲҶгҖӮз”ұдәҺжҲ‘们йңҖиҰҒз”Ё2еҲ°nиҖҢдёҚжҳҜ1еҲ°n-1ж Үи®°еү©дёӢзҡ„еӣҫпјҢжҲ‘们йңҖиҰҒеҜ№еҪ’зәіеҒҮи®ҫеҒҡзӮ№ж”№еҠЁгҖӮ
еҪ’зәіеҒҮи®ҫ2пјҡжҲ‘们зҹҘйҒ“дҫқжҚ®й—®йўҳзҡ„жқЎд»¶еҰӮдҪ•дҪҝз”Ёn-1дёҚеҗҢж Үи®°зҡ„йӣҶеҗҲеҺ»ж Үи®°дёҖдёӘжӢҘжңүn-1дёӘйЎ¶зӮ№зҡ„еӣҫгҖӮ
дёӢйқўз»ҷеҮәдёҺд№ӢеҜ№еә”зҡ„з®—жі•
жӢ“жү‘жҺ’еәҸз®—жі•
{G={V,E}:дёҖдёӘжңүеҗ‘ж— зҺҜеӣҫ};
begin
еҜ№жүҖжңүзҡ„йЎ¶зӮ№зҡ„е…ҘеәҰеҲқе§ӢеҢ–;
{еҸҜд»ҘйҖҡиҝҮж·ұеәҰдјҳе…Ҳжҗңзҙў}
G_label:=0;
for i:=1 to n do
if vi.indegree=0 then put vi in Queue;
repeat
remove vertex v from Queue;
G_label:=G_label + 1;
v_label:=G_label;
for all edges(v,w) do
w.indegree:=w.ingegree-1;
if w.indegree=0 then put w in Queue
until Queue is empty
end;
еӨҚжқӮеәҰпјҡеҲқе§ӢеҢ–е…ҘеәҰи®Ўж•°еҷЁйңҖиҰҒO(|V|+|E|)ж—¶й—ҙпјҲдҫӢеҰӮеңЁдҫӢеӯҗдёӯдҪҝз”Ёж·ұеәҰдјҳе…ҲжҗңзҙўпјүгҖӮжүҫеҲ°дёҖдёӘе…ҘеәҰдёә0зҡ„зӮ№иҰҒиҠұиҙ№еёёж•°ж—¶й—ҙпјҲи®ҝй—®йҳҹеҲ—пјүгҖӮжҜҸдёҖжқЎиҫ№пјҲv,wпјүиў«иҖғиҷ‘дёҖж¬ЎпјҲеҪ“vд»ҺйҳҹеҲ—дёӯиў«еҸ–еҮәж—¶пјүгҖӮеӣ жӯӨпјҢи®Ўж•°еҷЁйңҖиҰҒжӣҙж–°зҡ„ж¬Ўж•°зҡ„еӨҡе°‘е°ұжҳҜеӣҫдёӯиҫ№ж•°зӣ®зҡ„еӨҡе°‘гҖӮеӣ жӯӨз®—жі•зҡ„жү§иЎҢж—¶й—ҙе°ұжҳҜиҫ“е…Ҙ规模зҡ„зәҝжҖ§ж—¶й—ҙO(|V|+|E|)гҖӮ
жҖ»з»“пјҡиҝҷжҳҜеҸҰдёҖдёӘдҪҝз”ЁеҪ’зәіжі•зӣҙжҺҘи®ҫи®Ўз®—жі•зҡ„дҫӢеӯҗгҖӮиҝҷйҮҢзҡ„жҠҖе·§еңЁдәҺжҳҺжҷәйҖүжӢ©еҪ’зәіеәҸеҲ—гҖӮжҲ‘们дёҚжҳҜжӯҰж–ӯең°зј©еҮҸй—®йўҳ规模пјҢиҖҢжҳҜйҖүжӢ©з§»йҷӨдёҖдёӘзү№ж®Ҡзҡ„йЎ¶зӮ№гҖӮд»»дҪ•з»ҷе®ҡзҡ„й—®йўҳзҡ„规模йғҪеҸҜд»Ҙз”ЁеҫҲеӨҡеҸҜиғҪзҡ„ж–№жі•еҠ д»Ҙзј©еҮҸгҖӮжҖқжғіе°ұеңЁдәҺжҺўеҜ»еҗ„з§Қеҗ„ж ·зҡ„йҖүжӢ©з„¶еҗҺжөӢиҜ•дә§з”ҹзҡ„з®—жі•гҖӮжҲ‘们д»ҺеӨҡйЎ№ејҸи®Ўз®—иҝҷдёӘдҫӢеӯҗдёӯзңӢеҲ°д»Һе·Ұеҗ‘еҸіиҰҒжҜ”д»ҺеҸіеҗ‘е·ҰеҘҪгҖӮеҸҰдёҖдёӘйҖҡеёёзҡ„еҸҜиғҪжҖ§жҳҜеҜ№д»ҺдёҠеҫҖдёӢе’Ңд»ҺдёӢеҫҖдёҠиҝӣиЎҢжҜ”иҫғгҖӮеҗҢж ·д№ҹеҸҜиғҪжҜҸж¬ЎйҖ’еўһ2иҖҢдёҚжҳҜйҖ’еўһ1пјҢеҪ“然иҝҳжңүжӣҙеӨҡзҡ„еҸҜиғҪжғ…еҶөгҖӮжңүж—¶жңҖеҘҪзҡ„еҪ’зәіеәҸеҲ—з”ҡиҮіеҜ№дәҺжүҖжңүзҡ„иҫ“е…ҘжқҘиҜҙд№ҹжҳҜдёҚе°ҪзӣёеҗҢзҡ„гҖӮи®ҫи®ЎдёҖдёӘзү№ж®Ҡзҡ„з®—жі•еҺ»еҜ»жүҫдёҖдёӘеҜ№й—®йўҳжү§иЎҢ规模缩еҮҸзҡ„жңҖеҘҪзҡ„ж–№жі•жңүж—¶жҳҜеҖјеҫ—зҡ„гҖӮ
еҗҚдәәй—®йўҳгҖҗQ5гҖ‘пјҲдёҚзҹҘйҒ“дёҡз•ҢеҰӮдҪ•зҝ»иҜ‘пјү
еңЁз®—жі•и®ҫи®ЎдёӯжңүдёҖдёӘеҫҲжөҒиЎҢзҡ„з»ғд№ гҖӮиҝҷжҳҜдёҖдёӘйқһеёёеҘҪзҡ„дҫӢеӯҗпјҢиҜҘдҫӢеӯҗзҡ„и§Јзӯ”дёҚйңҖиҰҒжү«жҸҸе…ЁйғЁж•°жҚ®пјҲз”ҡиҮіжҳҜж•°жҚ®зҡ„йҮҚиҰҒзҡ„з»„жҲҗйғЁеҲҶпјүгҖӮеңЁnдёӘдәәдёӯпјҢдёҖдёӘеҗҚдәәиў«е®ҡд№үдёәе…¶д»–дәәйғҪи®ӨиҜҶдҪҶжҳҜиҮӘе·ұеҚҙдёҚи®ӨиҜҶе…¶д»–дәәзҡ„дәәгҖӮиҜҘй—®йўҳе°ұжҳҜеӯҳеңЁеҗҚдәәзҡ„жғ…еҶөдёӢзЎ®е®ҡеҗҚдәәпјҢеҸӘиғҪйҖҡиҝҮд»ҘдёҖз§ҚвҖңжӮЁеҘҪпјҢиҜ·й—®жӮЁи®ӨиҜҶз«ҷеңЁйӮЈйҮҢзҡ„дәәд№ҲпјҹвҖқзҡ„ж–№ејҸжҸҗй—®гҖӮпјҲеҒҮе®ҡжүҖжңүзҡ„еӣһзӯ”йғҪжҳҜжӯЈзЎ®зҡ„пјҢз”ҡиҮіжҳҜеҗҚдәәиҮӘе·ұд№ҹдјҡз»ҷеҮәзӯ”жЎҲпјүжҲ‘们зҡ„зӣ®ж ҮжҳҜи®©жңҖе°ҸеҢ–жҸҗй—®зҡ„ж¬Ўж•°гҖӮз”ұдәҺеӯҳеңЁn(n-1)/2еҜ№дәәпјҢеңЁжңҖеқҸзҡ„жғ…еҶөдёӢпјҢеҰӮжһңй—®йўҳиў«жӯҰж–ӯең°жҸҗеҮәпјҢжңүеҸҜиғҪйңҖиҰҒиҜўй—®n(n-1)ж¬Ўй—®йўҳжүҚиЎҢгҖӮжҲ‘们дёҚжё…жҘҡжҲ‘们иғҪжҜ”жңҖеқҸзҡ„жғ…еҶөеҒҡзҡ„жӣҙеҘҪгҖӮ
еңЁжҠҖжңҜдёҠпјҢеҰӮжһңжҲ‘们е»әз«ӢдёҖдёӘз”ЁйЎ¶зӮ№иЎЁзӨәдәәзҡ„жңүеҗ‘еӣҫпјҢеҪ“Aи®ӨиҜҶBе°ұжңүдёҖжқЎд»ҺAеҲ°Bзҡ„иҫ№пјҢйӮЈд№ҲдёҖдёӘеҗҚдәәе°ұеҜ№еә”дёҖдёӘжұҮзӮ№гҖӮпјҲйқһжңүж„Ҹзҡ„еҸҢе…іиҜӯпјүд№ҹе°ұдёҖдёӘе…ҘеәҰдёәn-1еҮәеәҰдёә0зҡ„йЎ¶зӮ№гҖӮиҜҘеӣҫеҸҜд»Ҙз”ЁдёҖдёӘnГ—nйӮ»жҺҘзҹ©йҳөжқҘиЎЁзӨәпјҢеҰӮжһң第iдёӘдәәи®ӨиҜҶ第jдёӘдәәйӮЈд№ҲеңЁиҜҘзҹ©йҳөдёӯдҪҚдәҺ第iиЎҢ第jеҲ—зҡ„дҪҚзҪ®иў«ж Үи®°дёә1пјҢеҗҰеҲҷе°ұдёә0гҖӮиҜҘй—®йўҳд№ҹе°ұжҳҜйҖҡиҝҮжҹҘжүҫзҹ©йҳөдёӯе°ҪеҸҜиғҪе°‘зҡ„жқЎзӣ®зЎ®е®ҡжұҮзӮ№гҖӮ
еғҸеҫҖеёёдёҖж ·пјҢжҲ‘们иҖғиҷ‘жңүn-1дёӘдәәе’ҢжңүnдёӘдәәж—¶й—®йўҳзҡ„дёҚеҗҢд№ӢеӨ„гҖӮ既然з”ұе®ҡд№үеҸҜзҹҘжңҖеӨҡеӯҳеңЁдёҖдёӘеҗҚдәәпјҢйӮЈиҝҷйҮҢе°ұжңүдёүз§ҚеҸҜиғҪгҖӮе…¶дёҖпјҢеҗҚдәәеңЁеүҚn-1дёӘдәәдёӯпјӣе…¶дәҢпјҢеҗҚдәәжҳҜ第nдёӘдәәпјӣе…¶дёүпјҢиҝҷйҮҢжІЎжңүеҗҚдәәгҖӮ第дёҖз§Қжғ…еҶөжңҖе®№жҳ“еӨ„зҗҶпјҢжҲ‘们еҸӘйңҖиҰҒж ёеҜ№з¬¬nдёӘдәәи®ӨиҜҶеҗҚдәәпјҢдҪҶжҳҜеҗҚдәә并дёҚи®ӨиҜҶ第nдёӘдәәзҡ„еұҖйқўжҳҜеҗҰеӯҳеңЁгҖӮе…¶д»–дёӨз§Қжғ…еҶөе°ұжҜ”иҫғеӣ°йҡҫдәҶпјҢеӣ дёәдёәдәҶзЎ®е®ҡ第nдёӘдәәжҳҜеҗҰжҳҜеҗҚдәәпјҢжҲ‘们еҸҜиғҪйңҖиҰҒжҸҗ2*(n-1)дёӘй—®йўҳгҖӮеңЁжңҖеқҸзҡ„жғ…еҶөдёӢпјҢиҝҷеҸҜиғҪдјҡеҜјиҮҙn*(n-1)дёӘй—®йўҳпјҲиҝҷжҳҜжҲ‘们иҜ•еӣҫйҒҝе…ҚеҸ‘з”ҹзҡ„пјүгҖӮжҲ‘们йңҖиҰҒеҸҰдёҖз§Қи§Јжі•гҖӮ
иҝҷйҮҢзҡ„жҠҖе·§еңЁдәҺд»ҺйҖҶеҗ‘иҖғиҷ‘иҝҷдёӘй—®йўҳгҖӮзЎ®е®ҡдёҖдёӘеҗҚдәәеҸҜиғҪеҫҲйҡҫпјҢдҪҶжҳҜзЎ®е®ҡжҹҗдёӘдәәдёҚжҳҜеҗҚдәәеҸҜиғҪиҰҒз®ҖеҚ•еҫҲеӨҡгҖӮжҜ•з«ҹпјҢеҫҲжҳҺжҳҫеңЁиҝҷйҮҢйқһеҗҚдәәиҰҒжҜ”еҗҚдәәеӨҡгҖӮжҠҠжҹҗдәәжҺ’йҷӨеҮәиҖғиҷ‘еҜ№жҠҠй—®йўҳ规模д»Һnзј©еҮҸеҲ°n-1жқҘиҜҙе·Із»Ҹи¶іеӨҹдәҶгҖӮжӯӨеӨ–пјҢжҲ‘们дёҚйңҖиҰҒжҺ’йҷӨеҮәзү№е®ҡзҡ„дәәпјҢд»»дҪ•дәәйғҪеҸҜд»ҘгҖӮеҒҮи®ҫжҲ‘们问AliceеҘ№жҳҜеҗҰи®ӨиҜҶBobпјҢеҰӮжһңеҘ№и®ӨиҜҶеҘ№е°ұдёҚдјҡжҳҜдёҖдёӘеҗҚдәәпјҢеҰӮжһңеҘ№дёҚи®ӨиҜҶ
йӮЈBobе°ұдёҚдјҡжҳҜдёҖдёӘеҗҚдәәгҖӮжҲ‘们еҸҜд»ҘйҖҡиҝҮдёҖдёӘй—®йўҳжҺ’йҷӨеҮә他们дёӯй—ҙзҡ„дёҖдёӘгҖӮ
зҺ°еңЁиҖғиҷ‘дёҠйқўеҲ—еҮәзҡ„дёүз§Қжғ…еҶөгҖӮжҲ‘们дёҚеҸӘжҳҜд»»ж„ҸжҢ‘йҖүдёҖдёӘдәәдҪңдёә第nдёӘдәәгҖӮжҲ‘们дҪҝз”ЁдёҠйқўзҡ„жҖқжғіеҺ»жҺ’йҷӨеҮәAliceе’ҢBobдёӯзҡ„дёҖдёӘпјҢ然еҗҺеҜ№е…¶дҪҷеҢ…еҗ«n-1дёӘдәәзҡ„й—®йўҳиҝӣиЎҢжұӮи§ЈгҖӮжҲ‘们дҝқиҜҒжғ…еҶө2дёҚдјҡеҸ‘з”ҹпјҢеӣ дёәжҺ’йҷӨеҮәеҺ»зҡ„дәәдёҚеҸҜиғҪжҳҜеҗҚдәәгҖӮжӯӨеӨ–пјҢеҰӮжһңжғ…еҶө3еҸ‘з”ҹпјҢд№ҹе°ұжҳҜиҜҙеңЁn-1дёӘдәәдёӯжІЎжңүеҗҚдәәпјҢйӮЈеңЁnдёӘдәәдёӯд№ҹдёҚдјҡжңүеҗҚдәәгҖӮеҸӘжңүжғ…еҶө1еӯҳеңЁпјҢдҪҶжҳҜжӯЈеҰӮдёҠйқўжҸҗеҲ°зҡ„пјҢиҝҷз§Қжғ…еҶөеҫҲз®ҖеҚ•гҖӮеҰӮжһңеңЁn-1дёӘдәәдёӯеӯҳеңЁдёҖдёӘеҗҚдәәпјҢеҸӘйңҖиҰҒжҸҗеҮәдёӨдёӘй—®йўҳе°ұеҸҜд»ҘзЎ®е®ҡж•ҙдёӘйӣҶеҗҲдёӯжҳҜеҗҰеӯҳеңЁеҗҚдәәдәҶгҖӮеҗҰеҲҷе°ұдёҚдјҡжңүеҗҚдәәеӯҳеңЁгҖӮ
жүҖеҫ—еҲ°зҡ„з®—жі•еҰӮдёӢгҖӮжҲ‘们问AжҳҜеҗҰи®ӨиҜҶBпјҢж №жҚ®Aзҡ„еӣһзӯ”жҺ’йҷӨжҺү他们其дёӯзҡ„дёҖдёӘгҖӮеҒҮи®ҫжҺ’йҷӨзҡ„жҳҜAпјҢ然еҗҺжҲ‘们еңЁеү©дёӢзҡ„n-1дёӘдәәдёӯеҜ»жүҫпјҲйҖҡиҝҮеҪ’зәіжі•пјүдёҖдёӘеҗҚдәәгҖӮеҰӮжһңжІЎжңүеҗҚдәәпјҢйӮЈд№Ҳз®—жі•е°ұз»ҲжӯўгҖӮеҗҰеҲҷжҲ‘д»¬ж ёе®һAи®ӨиҜҶеҗҚдәәдҪҶжҳҜеҗҚдәәдёҚи®ӨиҜҶAиҝҷз§ҚеұҖйқўгҖӮдёӢйқўз»ҷеҮәдёҖдёӘйқһйҖ’еҪ’зҡ„з®—жі•е®һзҺ°гҖӮ
еҗҚдәәз®—жі•пјҲе·ІзҹҘnГ—nзҡ„еёғе°”зҹ©йҳөпјү
begin
i:=1;
j:=2;
next:=2;
{еңЁз¬¬дёҖжӯҘдёӯжҲ‘们жҺ’йҷӨдәҶйҷӨдәҶдёҖдёӘеҖҷйҖүдәәд»ҘеӨ–зҡ„жүҖжңүдәә}
while nextвүӨn do
next:=next+1;
if Know[i,j] then i:=next;
else j:=next;
{жҲ‘们жҺ’йҷӨiе’Ңjдёӯзҡ„дёҖдёӘ}
if i=n+1 then candidate:=j else candidate:=i;
{зҺ°еңЁжҲ‘д»¬ж ёе®һиҜҘеҖҷйҖүдәәжҳҜеҗҰзЎ®е®һжҳҜеҗҚдәә}
wrong:=false;k:=1;
Know[candidate,candidate]:=false;
{еҸӘжҳҜдёҖдёӘз”ЁжқҘжөӢиҜ•зҡ„иҷҡжӢҹеҸҳйҮҸ}
while not wrong and kвүӨn do
if Know[candidate,k] then wrong:=true;
if not Know[k,candidate] then
if candidate вү k then wrong:=true;
k:=k+1пјӣ
if not wrong then printвҖқcandidate is a celebrity!вҖқ
end;
еӨҚжқӮеәҰпјҡиҝҷйҮҢжңҖеӨҡеҸӘйңҖиҰҒжҸҗ3*(n-1)дёӘй—®йўҳгҖӮеңЁз¬¬дёҖжӯҘдёӯжҸҗn-1дёӘй—®йўҳд»ҺиҖҢд»ҺеҖҷйҖүдәәдёӯжҺ’йҷӨжҺүn-1дёӘдәәгҖӮдёәдәҶзЎ®е®ҡйӮЈдёӘеҖҷйҖүдәәжҳҜеҗҰжҳҜеҗҚдәәжңҖеӨҡеҸӘйңҖиҰҒжҸҗ2*(n-1)дёӘй—®йўҳгҖӮдёҠйқўз»ҷеҮәзҡ„и§Јзӯ”иЎЁжҳҺеҸҜд»ҘеңЁйӮ»жҺҘзҹ©йҳөдёӯд»…жҹҘжүҫO(n)жқЎи®°еҪ•е°ұиғҪзЎ®е®ҡдёҖдёӘеҗҚдәәпјҢе°Ҫз®Ўд»ҺжҺЁзҗҶдёҠи®Өдёәй—®йўҳзҡ„и§Јжі•дёҺn(n-1)йЎ№иҫ“е…ҘйғҪеҜҶеҲҮзӣёе…ігҖӮпјҲиҝҷйҮҢд№ҹеҸҜиғҪиҠӮзңҒжҺүйўқеӨ–зҡ„log2(n)гҖҗеҸ–дёӢйҷҗгҖ‘ж¬ЎжҸҗй—®пјҢеҸӘйңҖиҰҒеңЁйӘҢиҜҒиҝҮзЁӢдёӯд»ҘеҸҠжҸҗй—®жҺ’йҷӨиҝҮзЁӢдёӯжіЁж„ҸйҒҝе…ҚйҮҚеӨҚеҚіеҸҜпјү
жҖ»з»“пјҡиҝҷдёӘжһҒдҪізҡ„и§Јжі•зҡ„ж ёеҝғжҖқжғіеңЁдәҺз”ЁдёҖз§ҚжҳҺжҷәзҡ„ж–№ејҸжҠҠй—®йўҳ规模д»Һnзј©еҮҸеҲ°n-1гҖӮиҝҷдёӘдҫӢеӯҗиЎЁжҳҺдәҶжңүж—¶еҖҷеңЁжӣҙжңүж•Ҳзҡ„иҝӣиЎҢй—®йўҳ规模зҡ„зј©еҮҸдёҠиҠұдёҖдәӣеҠӘеҠӣпјҲеңЁиҜҘдҫӢеӯҗдёӯжҸҗеҮәдёҖдёӘз–‘й—®пјүжҳҜеҖјеҫ—зҡ„гҖӮжӯӨеӨ–пјҢйҖҶеҗ‘жҖқз»ҙеңЁжң¬й—®йўҳдёӯжҳҫеҫ—еҫҲжңүз”ЁгҖӮдёҺе…¶еҺ»еҜ»жүҫдёҖдёӘеҗҚдәәжҲ‘们дёҚеҰӮе°қиҜ•еҺ»жҺ’йҷӨйқһеҗҚдәәгҖӮиҝҷеңЁж•°еӯҰиҜҒжҳҺж—¶з»Ҹеёёз”ЁеҲ°гҖӮдёҖдёӘдәәдёҚйңҖиҰҒзӣҙжҺҘеҺ»е°қиҜ•и§ЈеҶій—®йўҳгҖӮжңүж—¶и§ЈеҶіиғҪеӨҹз»ҷеҺҹе…Ҳй—®йўҳеёҰжқҘи§Јзӯ”зҡ„зӣёе…ій—®йўҳиҰҒз®ҖеҚ•дёҖдәӣгҖӮдёәдәҶжүҫеҲ°иҝҷдәӣзӣёе…ізҡ„й—®йўҳпјҢеңЁејҖе§Ӣж—¶дҪҝз”ЁжҲҗе“ҒпјҲж•°еӯҰиҜҒжҳҺдёӯзҡ„еҫ—еҲ°зҡ„е®ҡзҗҶпјүпјҢ然еҗҺйҖҶеҗ‘иҝӣиЎҢжҲ‘们зҡ„е·ҘдҪңзңӢзңӢе®һзҺ°иҝҷдёӘжҲҗе“ҒйңҖиҰҒд»Җд№ҲдёңиҘҝпјҢиҝҷеҫҖеҫҖжҳҜеҫҲжңүз”Ёзҡ„еҒҡжі•гҖӮ
еҠ ејәеҪ’зәіеҒҮи®ҫ
еңЁз”ЁеҪ’зәіжі•иҜҒжҳҺж•°еӯҰе®ҡзҗҶж—¶пјҢеҠ ејәеҪ’зәіеҒҮи®ҫиў«еҪ“еҒҡдёҖз§ҚеҫҲйҮҚиҰҒзҡ„жҠҖе·§дҪҝз”ЁгҖӮеҪ“е°қиҜ•дҪҝз”ЁдёҖдёӘеҪ’зәіиҜҒжҳҺж—¶еёёеёёдјҡйҒҮеҲ°дёӢйқўзҡ„жғ…еҶөгҖӮе®ҡзҗҶз”ЁP(n)иЎЁзӨәпјҢеҪ’зәіеҒҮи®ҫеҸҜд»Ҙз”ЁP(n-1)иЎЁзӨәпјҢиҰҒиҜҒжҳҺз»“и®әP(n-1)жҺЁеҜјеҮәP(n)гҖӮеҫҲеӨҡжғ…еҶөдёӢеҸҜд»ҘеҠ дёҠеҸҰдёҖдёӘеҒҮи®ҫпјҢз§°дёәQпјҢеңЁиҝҷдёӘеҒҮи®ҫдёӢиҜҒжҳҺдјҡеҸҳеҫ—жӣҙз®ҖеҚ•гҖӮд№ҹе°ұжҳҜиҜҙпјҢиҜҒжҳҺP(n-1)е’ҢQжҺЁеҜјеҮәP(n)иҰҒжӣҙеҠ е®№жҳ“гҖӮиҝҷз§Қз»“еҗҲзҡ„еҒҮи®ҫзңӢдёҠеҺ»жҳҜжӯЈзЎ®зҡ„дҪҶжҳҜиҝҳдёҚжё…жҘҡеҰӮдҪ•еҺ»иҜҒжҳҺгҖӮжҠҖе·§еңЁдәҺеңЁеҪ’зәіеҒҮи®ҫдёӯеҠ дёҠQ(еҰӮжһңеҸҜиғҪзҡ„иҜқ)гҖӮзҺ°еңЁйңҖиҰҒиҜҒжҳҺ[Pе’ҢQ](n-1)жҺЁеҜјеҮә[Pе’ҢQ](n)гҖӮз»“еҗҲзҡ„е®ҡзҗҶ[Pе’ҢQ]е’Ңд»…жңүPзӣёжҜ”жҳҜдёҖдёӘжӣҙејәзҡ„е®ҡзҗҶпјҢдҪҶжҳҜжңүж—¶еҖҷжӣҙејәзҡ„е®ҡзҗҶеҚҙжӣҙе®№жҳ“еҺ»иҜҒжҳҺпјҲPolyaз§°иҝҷдёӘеҺҹзҗҶдёәвҖңеҸ‘жҳҺ家зҡ„жӮ–и®әвҖқпјүгҖӮиҝҷдёӘиҝҮзЁӢеҸҜд»ҘеҸҚеӨҚпјҢеҠ дёҠжӯЈзЎ®иЎҘе……зҡ„еҒҮи®ҫпјҢе®ҡзҗҶзҡ„иҜҒжҳҺеҸҳеҫ—з®ҖеҚ•гҖӮжҲ‘们еңЁиЎЁиҫҫејҸи®Ўз®—е’Ңзәҝж®өеҢ…еҗ«й—®йўҳдёӯе·Із»ҸеҲқжӯҘзңӢеҲ°дәҶиҝҷдёӘеҺҹзҗҶгҖӮ
еңЁиҝҷйғЁеҲҶдёӯжҲ‘们з»ҷеҮәдёӨдёӘдҫӢеӯҗжқҘеұ•зҺ°еҠ ејәеҪ’зәіеҒҮи®ҫзҡ„иҝҗз”ЁгҖӮ第дёҖдёӘй—®йўҳеҫҲз®ҖеҚ•пјҢдҪҶе®ғйҳҗжҳҺдәҶдҪҝз”Ёиҝҷз§ҚжҠҖе·§ж—¶жңҖеёёи§Ғзҡ„й”ҷиҜҜпјҢд№ҹе°ұжҳҜеҝҪи§ҶдәҶеҠ е…ҘйўқеӨ–еҒҮи®ҫиҝҷдёӘдәӢе®һд»ҺиҖҢеҝҳи®°жӣҙж–°иҜҒжҳҺиҝҮзЁӢгҖӮжҚўеҸҘиҜқиҜҙпјҢиҜҒжҳҺP(n-1)е’ҢQжҺЁеҜјеҮәP(n)ж—¶жІЎжңүжіЁж„ҸеҲ°QжҳҜиў«еҒҮи®ҫзҡ„гҖӮжҲ‘们еҸҜд»ҘжҠҠиҝҷз§ҚиҪ¬жҚўзұ»жҜ”дёҺи§ЈеҶіжӣҙе°Ҹзҡ„й—®йўҳпјҢдёҚиҝҮиҜҘй—®йўҳе’ҢеҺҹе…Ҳзҡ„й—®йўҳе·Із»ҸдёҚжҳҜе®Ңе…ЁдёҖж ·зҡ„дәҶгҖӮ第дәҢдёӘдҫӢеӯҗжӣҙеӨҚжқӮдёҖдәӣгҖӮ
еңЁдәҢеҸүж ‘дёӯи®Ўз®—е№іиЎЎеӣ еӯҗгҖҗQ6гҖ‘
еҒҮи®ҫTжҳҜдёҖдёӘд»Ҙrдёәж №зҡ„дәҢеҸүж ‘гҖӮиҠӮзӮ№vзҡ„й«ҳеәҰе°ұжҳҜvе’Ңж ‘дёӯжңҖеә•еұӮзҡ„еҸ¶еӯҗд№Ӣй—ҙзҡ„и·қзҰ»пјҲеә”иҜҘжҳҜиҠӮзӮ№дёӢж–№зҡ„ж ‘зҡ„жңҖеә•еұӮеҸ¶еӯҗпјүгҖӮиҠӮзӮ№vзҡ„е№іиЎЎеӣ еӯҗиў«е®ҡд№үдёәиҠӮзӮ№vзҡ„е·Ұеӯ©еӯҗе’Ңе®ғзҡ„еҸіеӯ©еӯҗпјҲжҲ‘们еҒҮи®ҫдёҖдёӘиҠӮзӮ№зҡ„еӯ©еӯҗиў«ж Үи®°дёәе·Ұе’ҢеҸіпјүй«ҳеәҰд№Ӣе·®гҖӮеӣҫ3з»ҷеҮәдәҶдёҖжЈөж ‘пјҢеңЁж ‘дёӯжҜҸдёӘиҠӮзӮ№з”Ёh/bжқҘж Үи®°пјҢhжҳҜиҠӮзӮ№зҡ„й«ҳеәҰпјҢbжҳҜиҠӮзӮ№зҡ„е№іиЎЎеӣ еӯҗгҖӮ
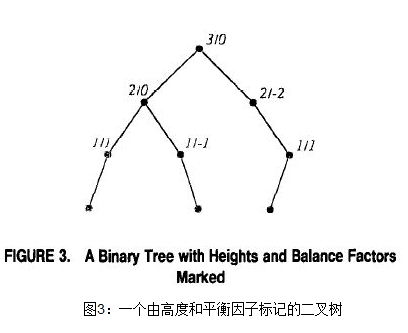
й—®йўҳпјҡз»ҷеҮәдёҖдёӘжӢҘжңүnдёӘиҠӮзӮ№зҡ„ж ‘пјҢи®Ўз®—е®ғжүҖжңүиҠӮзӮ№зҡ„е№іиЎЎеӣ еӯҗгҖӮ
жҲ‘们дҪҝз”Ёеҹәжң¬зҡ„еҪ’зәіз®—жі•д»ҘеҸҠзӣҙжҲӘдәҶеҪ“зҡ„еҪ’зәіеҒҮи®ҫпјҡ
еҪ’зәіеҒҮи®ҫпјҡжҲ‘们已з»ҸзҹҘйҒ“еҰӮдҪ•еҺ»и®Ўз®—е°ҸдәҺnдёӘиҠӮзӮ№зҡ„е№іиЎЎеӣ еӯҗгҖӮ
жңҖеҹәжң¬зҡ„n=1зҡ„дҫӢеӯҗеҫҲз®ҖеҚ•гҖӮз»ҷе®ҡдёҖдёӘжӢҘжңүn>1иҠӮзӮ№зҡ„дәҢеҸүж ‘пјҢжҲ‘们移еҺ»ж №иҠӮзӮ№пјҢ然еҗҺз”ЁйҖ’еҪ’зҡ„ж–№жі•и§ЈеҶіеү©дёӢзҡ„еӯҗж ‘гҖӮжҲ‘们йҖүжӢ©з§»еҺ»ж №иҠӮзӮ№еӣ дёәдёҖдёӘиҠӮзӮ№зҡ„е№іиЎЎеӣ еӯҗд»…д»…дҫқиө–дәҺиҠӮзӮ№дёӢйқўзҡ„иҠӮзӮ№гҖӮжҲ‘们зҺ°еңЁе·Із»ҸзҹҘйҒ“еҮәдәҶж №иҠӮзӮ№д»ҘеӨ–е…¶д»–жүҖжңүиҠӮзӮ№зҡ„е№іиЎЎеӣ еӯҗгҖӮдҪҶжҳҜж №иҠӮзӮ№зҡ„е№іиЎЎеӣ еӯҗдёҚжҳҜдҫқиө–дәҺе®ғзҡ„еӯ©еӯҗзҡ„е№іиЎЎеӣ еӯҗиҖҢжҳҜдҫқиө–дәҺе®ғзҡ„еӯ©еӯҗзҡ„й«ҳеәҰгҖӮеӣ жӯӨпјҢдёҖдёӘз®ҖеҚ•зҡ„еҪ’зәіжі•ж— жі•йҖӮз”ЁдәҺиҝҷдёӘдҫӢеӯҗгҖӮжҲ‘们йңҖиҰҒзҹҘйҒ“ж №иҠӮзӮ№еӯ©еӯҗзҡ„й«ҳеәҰгҖӮжҖқжғіе°ұеңЁдәҺеңЁеҺҹе…Ҳзҡ„й—®йўҳдёӯеҠ дёҠй«ҳеәҰжҹҘиҜўиҝҷдёӘй—®йўҳгҖӮ
еҠ ејәзҡ„еҪ’зәіеҒҮи®ҫпјҡжҲ‘们已з»ҸзҹҘйҒ“еҰӮдҪ•и®Ўз®—е°ҸдәҺnдёӘиҠӮзӮ№зҡ„е№іиЎЎеӣ еӯҗд»ҘеҸҠе®ғ们зҡ„й«ҳеәҰгҖӮ
еҶҚдёҖж¬Ўзҡ„пјҢеҹәжң¬й—®йўҳеҫҲз®ҖеҚ•гҖӮзҺ°еңЁиҖғиҷ‘ж №иҠӮзӮ№ж—¶еҸҜд»Ҙз®ҖеҚ•йҖҡиҝҮжҜ”иҫғе®ғзҡ„еӯ©еӯҗзҡ„й«ҳеәҰзЎ®е®ҡеҮәе®ғзҡ„е№іиЎЎеӣ еӯҗгҖӮжӯӨеӨ–пјҢж №иҠӮзӮ№зҡ„й«ҳеәҰд№ҹиғҪеӨҹиў«з®ҖеҚ•зЎ®е®ҡпјҢд№ҹе°ұжҳҜе®ғдёӨдёӘеӯ©еӯҗй«ҳеәҰзҡ„жңҖеӨ§еҖјеҠ дёҠ1гҖӮ
иҝҷдёӘз®—жі•зҡ„е…ій”®д№ҹе°ұжҳҜи§ЈеҶідёҖдёӘз®ҖеҚ•жӢ“еұ•зҡ„й—®йўҳгҖӮжҲ‘们д№ҹи®Ўз®—й«ҳеәҰиҖҢдёҚеҸӘжҳҜи®Ўз®—е№іиЎЎеӣ еӯҗгҖӮжӢ“еұ•еҗҺзҡ„й—®йўҳиҰҒжӣҙз®ҖеҚ•еӣ дёәй«ҳеәҰжҳҜеҫҲе®№жҳ“и®Ўз®—еҮәжқҘзҡ„гҖӮеңЁеҫҲеӨҡжғ…еҶөдёӢпјҢи§ЈеҶідёҖдёӘжӣҙејәзҡ„й—®йўҳеҸҚиҖҢжӣҙз®ҖеҚ•гҖӮиҝҷеҜ№дәҺеҪ’зәіжі•иҜҙе°Өе…¶жӯЈзЎ®гҖӮдҪҝз”ЁеҪ’зәіжі•пјҢжҲ‘们仅йңҖиҰҒжҠҠдёҖдёӘе°Ҹй—®йўҳжӢ“еұ•жҲҗдёҖдёӘжӣҙеӨ§зҡ„й—®йўҳгҖӮеҰӮжһңи§Јжі•жӣҙе®ҪжіӣпјҲеӣ дёәй—®йўҳиў«жӢ“еұ•дәҶпјүйӮЈд№ҲеҪ’зәіжӯҘйӘӨеҸҜиғҪиҰҒжӣҙз®ҖеҚ•еӣ дёәжҲ‘们жңүжӣҙеӨҡзҡ„дёңиҘҝеҸҜз”ЁгҖӮеңЁиҜҘй—®йўҳдёӯеёёи§Ғзҡ„дёҖдёӘй”ҷиҜҜжҳҜеҝҳи®°е…¶дёӯжңүдёӨдёӘдёҚеҗҢзҡ„еҸҳйҮҸпјҢиҖҢдё”иҝҷдёӨдёӘеҸҳйҮҸеҝ…йЎ»иҰҒеҚ•зӢ¬и®Ўз®—гҖӮ
жңҖиҝ‘еҜ№гҖҗQ7гҖ‘
й—®йўҳпјҡз»ҷе®ҡе№ійқўдёҠдёҖдёӘзӮ№зҡ„еҚіеҸҜпјҢжүҫеҮәжңҖиҝ‘дёӨзӮ№д№Ӣй—ҙзҡ„и·қзҰ»гҖӮ
жңҖзӣҙжҺҘдҪҝз”ЁеҪ’зәіжі•зҡ„ж–№жі•жҳҜ移еҺ»дёҖдёӘзӮ№пјҢи§ЈеҶіn-1дёӘзӮ№зҡ„й—®йўҳпјҢ然еҗҺеҶҚиҖғиҷ‘йӮЈдёӘйўқеӨ–зҡ„зӮ№гҖӮ然иҖҢпјҢеҰӮжһңд»ҺеҜ№n-1дёӘзӮ№зҡ„жғ…еҶөзҡ„жұӮи§Јдёӯд»…д»…зҹҘйҒ“他们дёӯй—ҙзҡ„жңҖе°Ҹи·қзҰ»пјҢйӮЈд№Ҳд»ҺйўқеӨ–зӮ№еҲ°е…¶дҪҷn-1дёӘзӮ№зҡ„и·қзҰ»йғҪйңҖиҰҒиў«и®Ўз®—еҮәжқҘгҖӮиҝҷж ·дҪҝеҫ—и®Ўз®—и·қзҰ»зҡ„жҖ»ж¬Ўж•°еҸҳжҲҗn-1+n-2+вҖҰ+1=n(n-1)/2гҖӮпјҲиҝҷе…¶е®һжҳҜдёҖдёӘзӣҙжҺҘжҜ”иҫғжҜҸдёӨзӮ№зҡ„з®—жі•пјүжҲ‘们жғіжүҫеҲ°дёҖдёӘжӣҙеҝ«зҡ„и§Јжі•гҖӮ
дёҖз§ҚеҲҶжІ»з®—жі•
еҪ’зәіеҒҮи®ҫеҰӮдёӢжүҖзӨә
еҪ’зәіеҒҮи®ҫпјҡжҲ‘们已з»ҸзҹҘйҒ“еңЁе№ійқўдёҠеҰӮдҪ•еҺ»жҹҘжүҫе°‘дәҺnдёӘзӮ№дёӯд»»ж„ҸдёӨзӮ№д№Ӣй—ҙзҡ„жңҖзҹӯи·қзҰ»гҖӮ
既然жҲ‘们еҒҮи®ҫжҲ‘们иғҪеӨҹи§ЈеҶіе°‘дәҺnдёӘзӮ№зҡ„еӯҗй—®йўҳпјҢжҲ‘们еҸҜд»ҘжҠҠй—®йўҳзј©еҮҸдёәдёӨдёӘеҗ«жңүn/2дёӘзӮ№зҡ„еӯҗй—®йўҳгҖӮжҲ‘们еҒҮи®ҫnжҳҜ2зҡ„е№ӮпјҢиҝҷж ·жҲ‘们жҖ»еҸҜд»ҘжҠҠдёҖдёӘйӣҶеҗҲеҲҶжҲҗж•°йҮҸдёӨдёӘзӣёзӯүзҡ„йӣҶеҗҲгҖӮпјҲжҲ‘们еҶҚеҗҺйқўеҶҚи®Ёи®әиҝҷдёӘеҒҮи®ҫпјүжңүеҫҲеӨҡж–№жі•еҸҜд»ҘжҠҠдёҖдёӘзӮ№йӣҶеҲҶжҲҗдёӨдёӘзӣёзӯүзҡ„йғЁеҲҶгҖӮжҲ‘们еҸҜд»ҘиҮӘз”ұйҖүжӢ©жңҖеҘҪзҡ„ж–№жі•гҖӮжҲ‘们жғіиҰҒд»Һ规模иҫғе°Ҹй—®йўҳзҡ„и§Јжі•дёӯиҺ·еҫ—е°ҪеҸҜиғҪеӨҡжңүз”Ёзҡ„дҝЎжҒҜпјҢеӣ жӯӨжҲ‘们жғіиҰҒеңЁиҖғиҷ‘ж•ҙдёӘй—®йўҳж—¶е°ҪеҸҜиғҪеӨҡзҡ„дҝқжҢҒжңүж•ҲгҖӮзңӢиө·жқҘиҝҷйҮҢжҠҠй—®йўҳеҲҶи§ЈдёәдёӨдёӘдёҚзӣёе…іеҗ„еҗ«дёҖеҚҠе…ғзҙ зҡ„йғЁеҲҶжҳҜжңүйҒ“зҗҶзҡ„гҖӮеҪ“жҲ‘们жүҫеҲ°жҜҸдёӘеӯҗйӣҶдёӯжңҖе°Ҹзҡ„и·қзҰ»еҗҺпјҢжҲ‘们еҸӘйңҖиҰҒе…іеҝғйӮЈдәӣйқ иҝ‘йӣҶеҗҲиҫ№з•Ңзҡ„зӮ№д№Ӣй—ҙзҡ„и·қзҰ»гҖӮи·қзҰ»жқҘиҜҙпјҢеҜ№жүҖжңүзӮ№иҝӣиЎҢжҺ’еәҸжңҖз®ҖеҚ•зҡ„ж–№жі•жҳҜжҢүз…§е®ғ们зҡ„xеқҗж ҮиҝӣиЎҢжҺ’еәҸпјҢжҠҠе№ійқўз”ЁдёҖжқЎеһӮзӣҙзәҝиҝӣиЎҢеҲҶеүІд»ҺиҖҢжҠҠйӣҶеҗҲдёҖеҲҶдёә2пјҲи§Ғеӣҫ4пјүгҖӮпјҲеҰӮжһңжңүдёҖдәӣзӮ№дҪҚдәҺеһӮзӣҙзәҝдёҠжҲ‘们任ж„ҸжҠҠе®ғ们еҲҶй…Қз»ҷдёӨдёӘйӣҶеҗҲдёӯзҡ„дёҖдёӘпјҢд»ҺиҖҢзЎ®дҝқдёӨдёӘйӣҶеҗҲжңүзӣёзӯүзҡ„е…ғзҙ пјүжҲ‘们йҖүжӢ©иҝҷж ·еҲ’еҲҶзҡ„еҺҹеӣ жҳҜдҪҝеҫ—еҗҲ并解зӯ”ж—¶иҰҒеҒҡзҡ„е·ҘдҪңе°ҪеҸҜиғҪе°‘гҖӮеҰӮжһңиҝҷдёӨдёӘйғЁеҲҶд»Ҙжҹҗз§Қж–№ејҸдәӨеҸүзқҖпјҢйӮЈж ·дјҡдҪҝеҫ—еҜ№жңҖиҝ‘еҜ№зӮ№зҡ„жЈҖжҹҘеҸҳеҫ—жӣҙеӨҚжқӮгҖӮжҺ’еәҸйңҖиҰҒд»…иў«жү§иЎҢдёҖж¬ЎгҖӮ
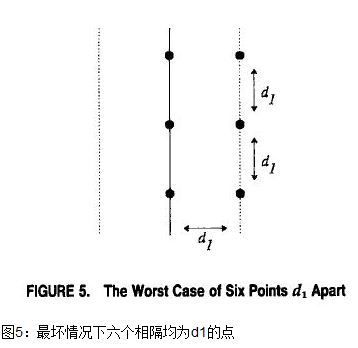
з»ҷе®ҡдёҖдёӘйӣҶеҗҲPпјҢжҲ‘们жҢүз…§дёҠйқўзҡ„еҒҡжі•жҠҠе®ғеҲҶи§ЈдёәP1е’ҢP2дёӨдёӘж•°йҮҸзӣёзӯүзҡ„еӯҗйӣҶгҖӮ然еҗҺжҲ‘们йҖҡиҝҮеҪ’зәіжі•еҺ»жҹҘжүҫжҜҸдёӘеӯҗйӣҶдёӯжңҖиҝ‘зҡ„дёӨзӮ№и·қзҰ»гҖӮжҲ‘们еҒҮи®ҫP1дёӯжңҖзҹӯзҡ„и·қзҰ»жҳҜd1пјҢP2дёӯжҳҜd2гҖӮдёҚеӨұдёҖиҲ¬жҖ§зҡ„пјҢжҲ‘们иҝӣдёҖжӯҘеҒҮи®ҫd1вүӨd2гҖӮжҲ‘们йңҖиҰҒжүҫеҲ°ж•ҙдёӘйӣҶеҗҲдёӯжңҖе°Ҹзҡ„и·қзҰ»пјҢд№ҹе°ұжҳҜиҜҙжҲ‘们йңҖиҰҒеҺ»жҹҘжүҫP1дёӯзҡ„дёҖдёӘзӮ№еҲ°P2дёӯзҡ„дёҖдёӘзӮ№жҳҜеҗҰжңүе°ҸдәҺd1зҡ„и·қзҰ»гҖӮйҰ–е…ҲжҲ‘们注ж„ҸеҲ°еҸӘйңҖиҰҒиҖғиҷ‘д»ҘдёӨйғЁеҲҶдёӯй—ҙзҡ„еһӮзӣҙзәҝдёәдёӯеҝғе®ҪеәҰдёә2d1зҡ„еёҰзҠ¶иҢғеӣҙеҶ…зҡ„зӮ№е°ұи¶іеӨҹдәҶпјҲи§Ғеӣҫ4пјүгҖӮеңЁиҜҘеҢәеҹҹеӨ–зҡ„зӮ№дёӯд»»ж„ҸдёӨзӮ№д№Ӣй—ҙдёҚеҸҜиғҪжӢҘжңүжҜ”d1жӣҙе°Ҹзҡ„и·қзҰ»гҖӮйҖҡиҝҮдёҠйқўзҡ„и§ӮеҜҹжҲ‘们йҖҡеёёиғҪеӨҹжҠҠеҫҲеӨҡзӮ№д»ҺиҖғиҷ‘дёӯжҺ’йҷӨпјҢдҪҶжҳҜеңЁжңҖеқҸзҡ„жғ…еҶөдёӢжүҖжңүзҡ„зӮ№йғҪеҸҜиғҪд»ҚдҪҚдәҺиҝҷжқЎеёҰзҠ¶еҢәеҹҹдёӯпјҢеҜ№дәҺе®ғ们жҲ‘д»¬ж— жі•дҪҝз”ЁзӣҙжҺҘзҡ„з®—жі•гҖӮ

еҸҰдёҖдёӘдёҚжҳҜйӮЈд№ҲжҳҺжҳҫзҡ„и§ӮеҜҹзӮ№жҳҜеҜ№дәҺеңЁеёҰдёӯзҡ„д»»ж„ҸзӮ№pпјҢеңЁеҸҰдёҖиҫ№жңүеҫҲе°‘зҡ„зӮ№еҲ°pзӮ№зҡ„и·қзҰ»иҰҒжҜ”d1е°ҸгҖӮеҺҹеӣ еңЁдәҺеңЁеёҰдёӯдёҖиҫ№зҡ„жүҖжңүзӮ№иҮіе°‘й—ҙйҡ”дёәd1.еҒҮи®ҫpжҳҜеёҰдёӯзҡ„дёҖдёӘзӮ№пјҢе®ғзҡ„yеқҗж ҮдёәypпјҢйӮЈд№ҲеҸӘйңҖиҰҒиҖғиҷ‘еңЁеҸҰдёҖиҫ№жңүеқҗж Үyqдё”ж»Ўи¶і|yp-yq|<d1зҡ„зӮ№еҚіеҸҜгҖӮеңЁеёҰзҡ„жҜҸдёҖиҫ№жңҖеӨҡжңүе…ӯдёӘиҝҷж ·зҡ„зӮ№пјҲи§Ғеӣҫ5дёӯжңҖеқҸзҡ„жғ…еҶөпјүгҖӮз»“жһңжҳҜеҰӮжһңжҲ‘们д»ҘзӮ№зҡ„yеқҗж Үй’ҲеҜ№жүҖжңүеёҰдёӯзҡ„зӮ№иҝӣиЎҢжҺ’еәҸ并且жҢүйЎәеәҸжү«жҸҸиҝҷдәӣзӮ№пјҢжҲ‘们еҸӘйңҖиҰҒжЈҖжҹҘжҜҸдёҖдёӘзӮ№е’ҢжҢүеәҸжҺ’еҲ—дёӯе®ғзҡ„еёёж•°дёӘйӮ»еұ…еҚіеҸҜпјҲиҖҢдёҚжҳҜе…ЁйғЁn-1дёӘзӮ№пјүгҖӮжҲ‘们еңЁиҝҷйҮҢзңҒз•ҘиҝҷдёӘдәӢе®һзҡ„иҜҒжҳҺпјҲи§ҒдҫӢеӯҗ[15]пјүгҖӮ
жңҖиҝ‘еҜ№з®—жі•{йҰ–ж¬Ўе°қиҜ•}
{p1,p2вҖҰpn:е№ійқўдёҠзҡ„зӮ№}
begin
жҢүз…§зӮ№зҡ„xеқҗж ҮеҜ№зӮ№иҝӣиЎҢжҺ’еәҸ{иҜҘжҺ’еәҸеҸӘеңЁејҖе§Ӣж—¶иҝҗиЎҢдёҖж¬Ў}
жҠҠйӣҶеҗҲеҲ’еҲҶжҲҗдёӨдёӘзӣёзӯүзҡ„йғЁеҲҶ
йҖ’еҪ’и®Ўз®—жҜҸдёӘйғЁеҲҶдёӯжңҖе°Ҹзҡ„и·қзҰ»
жҠҠdиөӢеҖјдёәдёӨдёӘжңҖе°Ҹи·қзҰ»дёӯзҡ„жңҖе°ҸеҖј
жҺ’йҷӨеҮәеҲҶеүІзәҝdи·қзҰ»иҢғеӣҙеӨ–зҡ„зӮ№
жҢүз…§yеқҗж ҮеҜ№еү©дёӢзҡ„зӮ№иҝӣиЎҢжҺ’еәҸ
жҢүз…§yйЎәеәҸжү«жҸҸиҝҷдәӣзӮ№е№¶и®Ўз®—жҜҸдёӘзӮ№е’Ңе®ғзҡ„дә”дёӘйӮ»еұ…д№Ӣй—ҙзҡ„и·қзҰ»{дәӢе®һдёҠпјҢ4дёӘе°ұеӨҹдәҶ}
if иҝҷдәӣи·қзҰ»дёӯжңүе°ҸдәҺdзҡ„ then
жӣҙж–°dеҖј
end;
еӨҚжқӮеәҰпјҡжҢүз…§xеқҗж ҮиҝӣиЎҢжҺ’еәҸйңҖиҰҒиҠұиҙ№O(nlogn)ж—¶й—ҙпјҢдҪҶжҳҜиҝҷд»…д»…йңҖиҰҒжү§иЎҢдёҖж¬ЎгҖӮ然еҗҺжҲ‘们解еҶіи§„жЁЎдёәn/2зҡ„дёӨдёӘеӯҗй—®йўҳгҖӮжҺ’йҷӨеҮәеёҰзҠ¶еҢәеҹҹд»ҘеӨ–зҡ„зӮ№еҸҜд»ҘеңЁO(n)зҡ„ж—¶й—ҙеҶ…е®ҢжҲҗгҖӮжҺҘдёӢжқҘеңЁжңҖеқҸзҡ„жғ…еҶөдёӢжҢүз…§yеқҗж ҮеҜ№еү©дёӢзҡ„зӮ№иҝӣиЎҢжҺ’еәҸйңҖиҰҒO(nlogn)жӯҘгҖӮжңҖз»ҲпјҢжү«жҸҸеёҰдёӯзҡ„зӮ№е№¶еңЁеәҸеҲ—дёӯжҠҠе®ғдёҺеёёж•°дёӘйӮ»еұ…иҝӣиЎҢжҜ”иҫғйңҖиҰҒO(n)жӯҘгҖӮжҖ»зҡ„жқҘиҜҙпјҢдёәдәҶеңЁnдёӘзӮ№дёӯжҹҘжүҫжңҖиҝ‘еҜ№пјҢжҲ‘们еңЁеҗ«жңүn/2дёӘзӮ№зҡ„еӯҗйӣҶдёӯжүҫеҲ°дёӨдёӘжңҖиҝ‘еҜ№пјҢ然еҗҺиҠұиҙ№O(nlogn)зҡ„ж—¶й—ҙеҺ»еҜ»жүҫдёӨдёӘеӯҗйӣҶд№Ӣй—ҙзҡ„жңҖиҝ‘еҜ№(еҠ дёҠдёҖж¬ЎжҢүз…§xеқҗж ҮиҝӣиЎҢжҺ’еәҸзҡ„ж—¶й—ҙO(nlogn))гҖӮеёҰжқҘзҡ„йҖ’жҺЁе…ізі»еҰӮдёӢпјҡ
T(n)=2T(n/2)+O(nlogn), T(2)=1.
иҝҷдёӘе…ізі»зҡ„и§Јзӯ”жҳҜT(n)=O(n(logn)^2)гҖӮиҝҷжҜ”дёҖдёӘдәҢж¬Ўзҡ„з®—жі•иҰҒеҘҪпјҢдҪҶжҳҜжҲ‘们еҸҜд»ҘеҒҡзҡ„жӣҙеҘҪгҖӮзҺ°еңЁжҲ‘们жқҘзңӢзңӢеҪ’зәіжі•жӣҙе·§еҰҷзҡ„дҪҝз”Ёж–№жі•гҖӮ
дёҖдёӘO(nlogn)зҡ„з®—жі•
иҝҷйҮҢзҡ„е…ій”®жҖқжғіжҳҜеҠ ејәеҪ’зәіеҒҮи®ҫгҖӮз”ұдәҺиҰҒжҺ’еәҸжҲ‘们еңЁеҗҲ并жӯҘйӘӨйңҖиҰҒиҠұиҙ№O(nlogn)зҡ„ж—¶й—ҙгҖӮе°Ҫз®ЎжҲ‘们зҹҘйҒ“еҰӮдҪ•зӣҙжҺҘи§ЈеҶіиҝҷдёӘй—®йўҳпјҢдҪҶжҳҜе®ғиҖ—ж—¶еӨӘй•ҝгҖӮжҲ‘们иғҪеӨҹеҒҡеҲ°еңЁи§ЈеҶіжҺ’еәҸй—®йўҳзҡ„еҗҢж—¶и§ЈеҶіжңҖиҝ‘еҜ№й—®йўҳд№ҲпјҹжҚўеҸҘиҜқиҜҙпјҢжҲ‘们жғіеҠ ејәеҪ’зәіеҒҮи®ҫжҠҠжҺ’еәҸдҪңдёәжңҖиҝ‘еҜ№й—®йўҳзҡ„дёҖйғЁеҲҶеҢ…еҗ«иҝӣжқҘд»ҺиҖҢеҫ—еҲ°дёҖдёӘжӣҙеҘҪзҡ„и§Јжі•гҖӮ
еҪ’зәіеҒҮи®ҫпјҡз»ҷе®ҡе№ійқўдёҠдёҖдёӘе°‘дәҺnдёӘзӮ№зҡ„йӣҶеҗҲпјҢжҲ‘们зҹҘйҒ“еҰӮдҪ•еҺ»еҜ»жүҫе®ғ们д№Ӣй—ҙзҡ„жңҖиҝ‘и·қзҰ»д№ҹзҹҘйҒ“еҰӮдҪ•жҢүз…§yеқҗж ҮжҺ’еәҸеҗҺиҫ“еҮәиҜҘйӣҶеҗҲгҖӮ
жҲ‘们已з»ҸзҹҘйҒ“еҰӮжһңзҹҘйҒ“еҰӮдҪ•жҺ’еәҸйӮЈиҜҘжҖҺж ·еҺ»еҜ»жүҫжңҖе°Ҹи·қзҰ»гҖӮеӣ жӯӨпјҢе”ҜдёҖйңҖиҰҒеҒҡзҡ„дәӢжғ…жҳҜеҰӮжһңжҲ‘们зҹҘйҒ“дёӨдёӘеҗ«жңүn/2зҡ„еӯҗйӣҶжҺ’еәҸйЎәеәҸйӮЈиҜҘеҰӮдҪ•еҜ№ж•ҙдёӘйӣҶеҗҲиҝӣиЎҢжҺ’еәҸгҖӮжҚўеҸҘиҜқиҜҙпјҢжҲ‘们йңҖиҰҒжҠҠдёӨдёӘжңүеәҸзҡ„еӯҗйӣҶеҗҲ并жҲҗдёҖдёӘжңүеәҸзҡ„йӣҶеҗҲгҖӮеҗҲ并еҸҜд»ҘеңЁзәҝжҖ§зҡ„ж—¶й—ҙеҶ…е®ҢжҲҗпјҲи§ҒдҫӢгҖҗ1гҖ‘пјүгҖӮеӣ жӯӨпјҢйҖ’еҪ’е…ізі»еҸҳжҲҗеҰӮдёӢпјҡ
T(n)=2T(n/2)+O(n), T(2)=1,
иҝҷд№ҹж„Ҹе‘ізқҖT(n)=O(nlogn)гҖӮиҜҘз®—жі•е’ҢдёҠдёҖдёӘз®—жі•е”ҜдёҖзҡ„еҢәеҲ«жҳҜжҢүз…§yеқҗж ҮжҺ’еәҸж—¶дёҚеҝ…жҜҸж¬ЎйғҪд»ҺеӨҙејҖе§ӢиҝӣиЎҢгҖӮеҪ“жҲ‘们жү§иЎҢж—¶дҪҝз”ЁеҠ ејәзҡ„еҪ’зәіеҒҮи®ҫжқҘиҝӣиЎҢжҺ’еәҸгҖӮдёӢйқўз»ҷеҮәзҡ„жҳҜж”№иҝӣеҗҺзҡ„з®—жі•гҖӮиҜҘз®—жі•жҳҜз”ұShamoе’ҢHoey(и§Ғ[15])жҸҗеҮәжқҘзҡ„гҖӮ
жңҖиҝ‘еҜ№з®—жі• {дёҖдёӘж”№иҝӣзҡ„зүҲжң¬}
{p1,p2вҖҰpn:е№ійқўдёҠзҡ„зӮ№}
begin
жҢүз…§xеқҗж ҮеҜ№зӮ№иҝӣиЎҢжҺ’еәҸ
{иҜҘжҺ’еәҸеҸӘжңүеңЁејҖе§Ӣж—¶жү§иЎҢдёҖж¬Ў}
жҠҠиҜҘйӣҶеҗҲеҲ’еҲҶдёәдёӨдёӘзӣёзӯүзҡ„йғЁеҲҶпјӣ
йҖ’еҪ’зҡ„жү§иЎҢдёӢйқўзҡ„жӯҘйӘӨ
и®Ўз®—жҜҸдёӘйғЁеҲҶдёӯжңҖе°Ҹзҡ„и·қзҰ»пјӣ
жҢүз…§yеқҗж ҮеҜ№жҜҸдёӘйғЁеҲҶзҡ„зӮ№иҝӣиЎҢжҺ’еәҸпјӣ
жҠҠдёӨдёӘжңүеәҸзҡ„еҲ—иЎЁеҗҲ并жҲҗдёҖдёӘжңүеәҸеҲ—иЎЁпјӣ
{иҜ·жіЁж„ҸжҲ‘们еҝ…йЎ»еңЁжҺ’йҷӨзӮ№д№ӢеүҚеҗҲ并пјҢжҲ‘们йңҖиҰҒдёәдёӢдёҖйҳ¶ж®өзҡ„йҖ’еҪ’жҸҗдҫӣжңүеәҸзҡ„е…ЁйӣҶ}
жҠҠdиөӢеҖјдёәдёӨдёӘжңҖе°Ҹи·қзҰ»дёӯзҡ„жңҖе°ҸиҖ…;
жҺ’йҷӨеҮәеҲҶеүІзәҝdи·қзҰ»иҢғеӣҙеӨ–зҡ„зӮ№
жҢүз…§yеқҗж ҮеҜ№еү©дёӢзҡ„зӮ№иҝӣиЎҢжҺ’еәҸ
жҢүз…§yйЎәеәҸжү«жҸҸиҝҷдәӣзӮ№е№¶и®Ўз®—жҜҸдёӘзӮ№е’Ңе®ғзҡ„дә”дёӘйӮ»еұ…д№Ӣй—ҙзҡ„и·қзҰ»{дәӢе®һдёҠпјҢ4дёӘе°ұеӨҹдәҶ}
if иҝҷдәӣи·қзҰ»дёӯжңүе°ҸдәҺdзҡ„ then
жӣҙж–°dеҖј
end;
жӣҙејәзҡ„еҪ’зәіжі•
жӣҙејәзҡ„еҪ’зәіжі•(жңүж—¶д№ҹиў«з§°дёәз»“жһ„еҢ–еҪ’зәіжі•)зҡ„жҖқжғіеңЁдәҺдёҚд»…д»…дҪҝз”Ёе®ҡзҗҶеҜ№дәҺn-1(жҲ–иҖ…е…¶д»–е°ҸдәҺnзҡ„еҖј)жҲҗз«Ӣзҡ„еҒҮи®ҫпјҢд№ҹдҪҝз”Ёе®ҡзҗҶеҜ№жүҖжңүk(1вүӨk<n)жҲҗз«Ӣзҡ„жӣҙејәеҒҮи®ҫгҖӮжҠҠиҝҷз§ҚжҠҖе·§иҪ¬жҚўеҲ°з®—жі•и®ҫи®ЎдёӯйңҖиҰҒз»ҙжҢҒдёҖдёӘеҗ«жңүжүҖжңүе°Ҹй—®йўҳи§Јжі•зҡ„ж•°жҚ®з»“жһ„гҖӮеӣ жӯӨпјҢиҜҘжҠҖе·§йҖҡеёёеј•иө·жӣҙеӨҡзҡ„з©әй—ҙеҚ з”ЁгҖӮжҲ‘们з»ҷеҮәдёҖдёӘдҪҝз”Ёиҝҷз§ҚжҠҖе·§зҡ„дҫӢеӯҗгҖӮ
иғҢеҢ…й—®йўҳгҖҗQ8гҖ‘
иғҢеҢ…й—®йўҳжҳҜдёҖдёӘеҫҲйҮҚиҰҒзҡ„дјҳеҢ–й—®йўҳгҖӮе®ғд№ҹжңүеҫҲеӨҡдёҚеҗҢзҡ„еҸҳз§ҚпјҢдҪҶиҝҷйҮҢжҲ‘们еҸӘи®Ёи®әе…¶дёӯзҡ„дёҖз§ҚеҸҳз§ҚгҖӮ
й—®йўҳпјҡиҝҷйҮҢжңүnдёӘдёҚеҗҢеӨ§е°Ҹзҡ„зү©е“ҒгҖӮ第iдёӘзү©е“ҒжңүдёҖдёӘж•ҙеһӢзҡ„еӨ§е°ҸkiгҖӮй—®йўҳжҳҜжүҫеҲ°дёҖдёӘзү©е“Ғзҡ„еӯҗйӣҶдҪҝеҫ—иҜҘйӣҶеҗҲзҡ„еӨ§е°ҸжҖ»е’ҢжӯЈеҘҪдёәKпјҢжҲ–иҖ…жҲ‘们确е®ҡдёҚеӯҳеңЁиҝҷж ·зҡ„еӯҗйӣҶгҖӮжҚўеҸҘиҜқиҜҙпјҢз»ҷжҲ‘们дёҖдёӘеӨ§е°ҸдёәKзҡ„иғҢеҢ…жҲ‘们жғіжҠҠе®ғиЈ…ж»Ўзү©е“ҒгҖӮжҲ‘们жҠҠиҝҷдёӘй—®йўҳиЎЁзӨәдёәP(n,K)пјҢ第дёҖдёӘеҸӮж•°иЎЁзӨәзү©е“Ғзҡ„ж•°зӣ®пјҢ第дәҢдёӘеҸӮж•°иЎЁзӨәиғҢеҢ…зҡ„еӨ§е°ҸгҖӮжҲ‘们еҒҮи®ҫеӨ§е°ҸжҳҜеӣәе®ҡзҡ„гҖӮжҲ‘们用P(j,k)(jвүӨnдё”kвүӨK)иЎЁзӨәжңүjдёӘзү©е“Ғе’ҢеӨ§е°Ҹдёәkзҡ„иғҢеҢ…й—®йўҳгҖӮдёәдәҶз®ҖеҢ–пјҢжҲ‘们仅关еҝғй—®йўҳзҡ„з»“и®әпјҢд№ҹе°ұжҳҜеҶіе®ҡжҳҜеҗҰеӯҳеңЁиҝҷж ·зҡ„дёҖдёӘи§Јзӯ”гҖӮеңЁеҗҺйқўжҲ‘们з»ҷеҮәеҰӮдҪ•еҺ»еҜ»жүҫеҲ°дёҖдёӘи§Јзӯ”гҖӮ
жҲ‘们йҰ–е…Ҳд»ҺжңҖзӣҙжҺҘзҡ„еҪ’зәіжі•ејҖе§ӢгҖӮ
еҪ’зәіеҒҮи®ҫпјҡжҲ‘们зҹҘйҒ“еҰӮдҪ•еҺ»и§ЈеҶіP(n-1,K)зҡ„й—®йўҳгҖӮ
еҹәжң¬жғ…еҶөеҫҲз®ҖеҚ•пјҢеҰӮжһңд»…жңүдёҖдёӘеӨ§е°ҸдёәKзҡ„зү©е“ҒжңүеҠһжі•и§ЈеҶігҖӮеҰӮжһңжңүи§ЈеҶіP(n-1,K)зҡ„еҠһжі•пјҢд№ҹе°ұжҳҜиҜҙеҰӮжһңжңүиғҪеӨҹжҠҠn-1дёӘзү©е“Ғж”ҫе…ҘиғҢеҢ…зҡ„ж–№жі•жҲ‘们е°ұз®—е®ҢжҲҗдәҶгҖӮжҲ‘们еҸӘйңҖиҰҒз®ҖеҚ•зҡ„дёҚдҪҝ用第nдёӘзү©е“ҒеҚіеҸҜгҖӮ然иҖҢпјҢеҒҮи®ҫжІЎжңүеҜ№P(n-1,K)зҡ„и§ЈеҶіж–№жі•пјҢжҲ‘们иғҪеӨҹдҪҝз”ЁиҝҷдёӘеҗҰе®ҡзҡ„з»“и®әд№Ҳпјҹзӯ”жЎҲжҳҜеҸҜд»Ҙзҡ„пјҢиҝҷд№ҹж„Ҹе‘ізқҖ第nдёӘзү©е“Ғеҝ…йЎ»иў«еҢ…еҗ«иҝӣеҺ»гҖӮеңЁиҝҷз§Қжғ…еҶөдёӢпјҢеү©дёӢзҡ„зү©е“Ғеҝ…йЎ»иЈ…е…ҘдёҖдёӘжӣҙе°Ҹзҡ„е®№йҮҸдёәK-knзҡ„иғҢеҢ…гҖӮжҲ‘们жҠҠй—®йўҳз®ҖеҢ–дёәдәҶдёӨдёӘжӣҙе°Ҹзҡ„й—®йўҳпјҡеҰӮжһңP(n,K)жңүи§ЈйӮЈд№ҲP(n-1,K)жҲ–иҖ…P(n-1,K-kn)дёӨиҖ…дёӯй—ҙеҝ…йЎ»жңүдёҖдёӘжңүи§ЈгҖӮдёәдәҶе®ҢжҲҗиҝҷдёӘз®—жі•жҲ‘们дёҚд»…йңҖиҰҒжұӮи§Је®№йҮҸдёәKзҡ„иғҢеҢ…й—®йўҳд№ҹйңҖиҰҒжұӮи§ЈеҜ№жңҖеӨ§е®№йҮҸдёәKзҡ„жүҖжңүиғҢеҢ…зҡ„й—®йўҳгҖӮпјҲиҝҷйҮҢеӯҳеңЁжҠҠиғҢеҢ…е®№йҮҸйҷҗеҲ¶еңЁдёҖдәӣеҮҸеҺ»kiеҗҺзҡ„еӨ§е°Ҹд№ӢдёӯпјҢдҪҶжҳҜд№ҹеҸҜиғҪдёҚеӯҳеңЁиҝҷж ·зҡ„йҷҗеҲ¶жқЎд»¶пјү
жӣҙејәзҡ„еҪ’зәіеҒҮи®ҫпјҡжҲ‘们已з»ҸзҹҘйҒ“еҜ№жүҖжңүзҡ„0вүӨkвүӨKеҰӮдҪ•еҺ»жұӮи§ЈP(n-1,k)гҖӮ
дёҠйқўзҡ„з®ҖеҢ–并дёҚдҫқиө–дәҺдёҖдёӘзү№е®ҡзҡ„kеҖјпјҢе®ғеҜ№жүҖжңүзҡ„kеҖјйғҪжҳҜжңүж•Ҳзҡ„гҖӮжҲ‘们еҸҜд»ҘдҪҝз”ЁиҝҷдёӘеҪ’зәіеҒҮи®ҫи§ЈеҶіжүҖжңүзҡ„0вүӨkвүӨKзҡ„P(n,k)й—®йўҳгҖӮжҲ‘们жҠҠP(n,k)з®ҖеҢ–дёәP(n-1,k)е’ҢP(n-1,k-kn)иҝҷдёӨдёӘй—®йўҳгҖӮпјҲеҰӮжһңk-kn<0жҲ‘们е°ұеҝҪз•Ҙ第дәҢдёӘй—®йўҳпјүиҝҷдёӨдёӘй—®йўҳйғҪеҸҜд»Ҙз”ЁеҪ’зәіжі•жұӮи§ЈгҖӮиҝҷжҳҜдёҖдёӘжңүж•Ҳзҡ„з®ҖеҢ–жҲ‘们д№ҹиғҪжүҫеҲ°дёҖдёӘз®—жі•пјҢдҪҶжҳҜиҜҘз®—жі•ж•ҲзҺҮдёҚй«ҳгҖӮжҲ‘们еҫ—еҲ°зҡ„д»…жҳҜ规模зЁҚе°ҸдёҖзӮ№зҡ„дёӨдёӘеӯҗй—®йўҳгҖӮеӣ иҖҢеңЁеҜ№и§„жЁЎзҡ„жҜҸжӯҘз®ҖеҢ–дёӯеӯҗй—®йўҳзҡ„дёӘж•°д№ҹжҳҜзҝ»еҖҚеўһй•ҝгҖӮз”ұдәҺеҜ№и§„жЁЎзҡ„з®ҖеҢ–еҸҜиғҪдёҚжҳҜйӮЈд№ҲзЎ®еҲҮпјҢз®—жі•еҸҜиғҪжҳҜжҢүз…§жҢҮж•°зә§еўһй•ҝгҖӮпјҲж №жҚ®kiзҡ„еҖјжқҘзЎ®е®ҡпјү
е№ёиҝҗзҡ„жҳҜпјҢеңЁеҫҲеӨҡжғ…еҶөдёӢеҜ№иҝҷз§Қй—®йўҳжҸҗй«ҳиҝҗиЎҢж•ҲзҺҮжҳҜеҸҜиЎҢзҡ„гҖӮдё»иҰҒзҡ„и§ӮеҜҹжҳҜеҸҜиғҪзҡ„й—®йўҳзҡ„жҖ»ж•°дёҚжҳҜеҫҲеӨҡгҖӮдәӢе®һдёҠпјҢжҲ‘们引е…ҘP(n,k)иҝҷдёӘи®°еҸ·жқҘиЎЁзӨәиҜҘй—®йўҳгҖӮеҜ№з¬¬дёҖдёӘеҸӮж•°еӯҳеңЁnз§ҚеҸҜиғҪжҖ§пјҢеҜ№дәҺ第дәҢдёӘеҸӮж•°еӯҳеңЁKз§ҚеҸҜиғҪжҖ§гҖӮжҖ»зҡ„жқҘиҜҙпјҢиҝҷйҮҢеҸӘжңүn*Kз§ҚдёҚеҗҢеҸҜиғҪжҖ§зҡ„й—®йўҳгҖӮеңЁжҜҸж¬Ўз®ҖеҢ–еҗҺеҜ№й—®йўҳж•°зӣ®зҝ»еҖҚдјҡеёҰжқҘжҢҮж•°иҝҗиЎҢж—¶й—ҙпјҢдҪҶжҳҜеҰӮжһңиҝҷйҮҢеҸӘжңүn*KдёӘдёҚеҗҢзҡ„й—®йўҳжҲ‘们иӮҜе®ҡеҜ№еҗҢдёҖдёӘй—®йўҳжұӮи§ЈдәҶеӨҡж¬ЎгҖӮеҰӮжһңжҲ‘们记дёӢдәҶжүҖжңүзҡ„и§Јзӯ”жҲ‘们е°ұдёҚйңҖиҰҒеҜ№еҗҢдёҖдёӘй—®йўҳжұӮи§ЈдёӨж¬ЎгҖӮиҝҷе®һйҷ…дёҠжҳҜеҠ ејәеҪ’зәіеҒҮи®ҫе’ҢдҪҝз”Ёжӣҙејәзҡ„еҪ’зәіжі•пјҲдҪҝз”ЁеҜ№жүҖжңүе·ІзҹҘзҡ„жӣҙе°Ҹ规模问йўҳиҖҢдёҚд»…д»…еҜ№n-1й—®йўҳи§Јзӯ”зҡ„еҒҮи®ҫпјүзҡ„з»“еҗҲгҖӮдёӢйқўжқҘзңӢзңӢжҲ‘们еҰӮдҪ•е®һзҺ°иҜҘж–№жі•гҖӮ
жҲ‘们жҠҠжүҖжңүе·ІзҹҘзҡ„з»“жһңеӯҳж”ҫеңЁдёҖдёӘnГ—Kзҡ„зҹ©йҳөдёӯгҖӮзҹ©йҳөдёӯ第ijдёӘдҪҚзҪ®еҢ…еҗ«зқҖP(i,j)зҡ„и§Јзӯ”дҝЎжҒҜгҖӮдҪҝз”ЁдёҠйқўжӣҙејәзҡ„еҪ’зәіеҒҮи®ҫеҗҺпјҢй—®йўҳз®ҖеҢ–дёәеҹәжң¬дёҠи®Ўз®—зҹ©йҳөзҡ„第nиЎҢеҖјеҚіеҸҜгҖӮ第nиЎҢзҡ„жҜҸдёӘжқЎзӣ®жҳҜйҖҡиҝҮе…¶дёҠзҡ„дёӨдёӘжқЎзӣ®и®Ўз®—еҫ—еҲ°зҡ„гҖӮеҰӮжһңжҲ‘们еҜ№жүҫеҲ°е®һйҷ…зҡ„йӣҶеҗҲж„ҹе…ҙи¶Јзҡ„иҜқпјҢжҲ‘们еҸҜд»ҘеңЁжҜҸдёӘдҪҚзҪ®еҠ дёҠдёҖдёӘж Үи®°еӯ—ж®өпјҢиҜҘеӯ—ж®өеҸҜд»ҘиЎЁзӨәеңЁйӮЈжӯҘж“ҚдҪңдёӯеҜ№еә”зҡ„зү©е“ҒжҳҜеҗҰиў«йҖүдёӯгҖӮж Үи®°еӯ—ж®өеҸҜд»Ҙд»Һ第(n,K)дёӘдҪҚзҪ®еҖ’жҺЁпјҢйӣҶеҗҲд№ҹеҸҜд»Ҙиў«еӨҚеҺҹгҖӮиҝҷдёӘз®—жі•еҲ—еңЁдёӢдёҖеҲ—йЎ¶йғЁгҖӮ
иғҢеҢ…з®—жі•{k1,k2вҖҰkn,K:ж•ҙеһӢ};
{еҰӮжһңеҜ№дәҺеүҚiдёӘе…ғзҙ е’Ңе®№йҮҸдёәjзҡ„иғҢеҢ…жңүи§ЈйӮЈд№ҲP[i,j].exist=trueпјҢеҰӮжһң第iдёӘе…ғзҙ еҢ…еҗ«еңЁи§ЈдёӯйӮЈд№ҲP[i,j].belong=true}
begin
P[0,00].exist:=true;
for j:=1 to n do
P[0,j].exist:=false;
for i:=1 to n do
for j:=0 to K do
P[i,j].exist:=false;{й»ҳи®ӨеҖј}
if P[i-1,j].exist then
P[i,j].exist:=true;
P[i,j].belong:=false;
else if j-kiвүҘ0 then
P[i-1,j-ki].exist then
P[i,j].exist:=true;
P[i,j].belong:=true;
end;
еӨҚжқӮеәҰпјҡзҹ©йҳөдёӯжңүnГ—KдёӘжқЎзӣ®пјҢд»ҺдёӨдёӘдёҚеҗҢжқЎзӣ®и®Ўз®—еҮәдёҖдёӘжқЎзӣ®йңҖиҰҒеёёж•°ж—¶й—ҙгҖӮеӣ жӯӨпјҢжҖ»зҡ„иҝҗиЎҢж—¶й—ҙжҳҜO(nK)гҖӮеҰӮжһңзү©е“Ғзҡ„еӨ§е°ҸдёҚжҳҜзү№еҲ«еӨ§пјҢйӮЈд№ҲKе°ұдёҚеҸҜиғҪеӨӘеӨ§е№¶дё”nKжҜ”nзҡ„жҢҮж•°иЎЁзӨәиҰҒе°ҸеҫҲеӨҡгҖӮпјҲеҰӮжһңKйқһеёёеӨ§жҲ–иҖ…жҳҜдёҖдёӘе®һж•°пјҢйӮЈд№Ҳиҝҷз§Қж–№жі•е°ұдёҚй«ҳж•ҲпјүеҰӮжһңжҲ‘们еҸӘе…іеҝғзЎ®е®ҡжҳҜеҗҰеӯҳеңЁдёҖдёӘи§Јзӯ”йӮЈд№Ҳзӯ”жЎҲе°ұеңЁP[n,K]дёӯгҖӮеҰӮжһңжҲ‘们еҜ№жүҫеҲ°е®һйҷ…зҡ„йӣҶеҗҲж„ҹе…ҙи¶ЈпјҢжҲ‘们еҸҜд»Ҙд»Һ第(n,K)дёӘжқЎзӣ®еҖ’жҺЁпјҢдҫӢеҰӮдҪҝз”ЁиғҢеҢ…зЁӢеәҸдёӯзҡ„belongж Үеҝ—дҪҚпјҢеңЁO(n)ж—¶й—ҙеҶ…еӨҚеҺҹиҝҷдёӘйӣҶеҗҲгҖӮ
з»“и®әпјҡжҲ‘们еҲҡжүҚдҪҝз”Ёзҡ„жҳҜдёҖз§Қеёёи§ҒжҠҖжңҜж–№жі•зҡ„дёҖдёӘе…·дҪ“е®һдҫӢпјҢиҜҘж–№жі•иў«з§°дёәеҠЁжҖҒ规еҲ’пјҢе®ғзҡ„жң¬иҙЁжҳҜе»әз«ӢдёҖдёӘе·ЁеӨ§зҡ„иЎЁпјҢеңЁиЎЁдёӯеЎ«е…Ҙе·ІзҹҘзҡ„д№ӢеүҚзҡ„и§Јзӯ”гҖӮиҜҘиЎЁжҳҜз”Ёиҝӯд»Јзҡ„ж–№жі•иҝӣиЎҢжһ„йҖ зҡ„гҖӮзҹ©йҳөдёӯзҡ„жҜҸдёӘжқЎзӣ®йғҪжҳҜд»Һе…¶дёҠжҲ–е·Ұдҫ§зҡ„е…¶д»–жқЎзӣ®и®Ўз®—еҫ—еҲ°зҡ„гҖӮдё»иҰҒзҡ„й—®йўҳжҳҜз”ЁдёҖз§ҚжңҖжңүж•Ҳзҡ„ж–№жі•иҝӣиЎҢиЎЁзҡ„жһ„йҖ гҖӮеҠЁжҖҒ规еҲ’еңЁй—®йўҳд»…иғҪиў«з®ҖеҢ–дёәеҮ дёӘдёҚжҳҜи¶іеӨҹе°Ҹзҡ„еӯҗй—®йўҳж—¶жҳҜжңүж•Ҳзҡ„гҖӮ
жңҖеӨ§зҡ„еҸҚдҫӢ
еңЁиҜҒжҳҺж•°еӯҰе®ҡзҗҶдёӯдёҖз§Қжңүзү№иүІе№¶дё”ејәеӨ§зҡ„жҠҖе·§жҳҜеҒҮи®ҫе®ҡзҗҶзҡ„еҸҚйқўжҲҗз«Ӣ然еҗҺжүҫеҲ°дёҖдёӘзҹӣзӣҫгҖӮйҖҡеёёиҝҷжҳҜз”ЁдёҖз§Қе®ҢжҲҗйқһе»әи®ҫжҖ§зҡ„ж–№ејҸе®һзҺ°зҡ„пјҢиҝҷеҜ№дәҺжҲ‘们зҡ„зұ»жҜ”дёҚжҳҜеҫҲжңүз”ЁгҖӮиҷҪ然жңүж—¶йҖҡиҝҮдёҖз§Қе’ҢеҪ’зәіжі•зұ»дјјзҡ„ж–№жі•иғҪеӨҹжүҫеҲ°дёҖдёӘзҹӣзӣҫгҖӮеҒҮи®ҫжҲ‘们жғіиҜҒжҳҺдёҖдёӘзЎ®е®ҡзҡ„еҸҳйҮҸPпјҲеңЁдёҖдёӘз»ҷе®ҡзҡ„й—®йўҳдёӯпјүиғҪеӨҹеҸ–еҲ°дёҖдёӘзЎ®е®ҡзҡ„еҖјnгҖӮ第дёҖжӯҘжҲ‘们з»ҷеҮәPиғҪеӨҹеҸ–еҲ°дёҖдёӘе°ҸеҖјпјҲеҹәжң¬жғ…еҶөпјүгҖӮ第дәҢжӯҘжҲ‘们еҒҮи®ҫPж— жі•еҸ–еҲ°nпјҢжҲ‘们еҸҜд»ҘиҖғиҷ‘е®ғиғҪеҸ–еҲ°зҡ„жңҖеӨ§еҖјk<nгҖӮжңҖеҗҺд»ҘеҸҠжңҖдё»иҰҒзҡ„жӯҘйӘӨжҳҜз»ҷеҮәдёҖдёӘзҹӣзӣҫпјҢйҖҡеёёй’ҲеҜ№жңҖеӨ§еҢ–зҡ„еҒҮи®ҫгҖӮжҲ‘们з»ҷеҮәдёҖдёӘз®—жі•и®ҫи®Ўзҡ„дҫӢеӯҗпјҢеңЁиҜҘдҫӢеӯҗдёӯиҝҷз§ҚжҠҖжңҜйқһеёёжңүз”ЁгҖӮ
зЁ еҜҶеӣҫдёӯзҡ„жңҖдјҳеҢ№й…ҚгҖҗQ9гҖ‘
еңЁж— еҗ‘еӣҫG=(V,E)дёӯдёҖдёӘеҢ№й…Қд№ҹе°ұжҳҜдёҖдёӘжІЎжңүе…¬е…ұйЎ¶зӮ№зҡ„иҫ№зҡ„йӣҶеҗҲгҖӮпјҲдёҖжқЎиҫ№еҜ№еә”дәҺдёӨдёӘзӮ№пјҢдёҖдёӘзӮ№дёҚеҸҜиғҪеҜ№еә”дәҺеӨҡдҪҷдёҖдёӘйЎ¶зӮ№пјүжңҖеӨ§еҢ№й…ҚжҳҜдёҖдёӘж— жі•жӢ“еұ•зҡ„й—®йўҳпјҢж„Ҹе‘ізқҖжүҖжңүе…¶д»–зҡ„иҫ№йғҪиҮіе°‘дёҺдёҖдёӘеҢ№й…Қзҡ„йЎ¶зӮ№зӣёиҝһгҖӮдёҖдёӘжңҖеӨ§еҢ№й…Қд№ҹе°ұжҳҜдёҖдёӘжңҖеӨ§йӣҶгҖӮпјҲдёҖдёӘжңҖеӨ§еҢ№й…ҚжҖ»жҳҜжңҖеӨ§зҡ„пјҢдҪҶжҳҜеҸҚиҝҮжқҘиҜҙеҚҙжңӘеҝ…жӯЈзЎ®пјүеңЁеӣҫдёӯдёҖдёӘжӢҘжңүnжқЎиҫ№е’Ң2nдёӘзӮ№зҡ„еҢ№й…Қиў«з§°дёәжңҖдјҳеҢ№й…ҚгҖӮпјҲжҳҫ然д№ҹжҳҜжңҖеӨ§зҡ„пјүеңЁиҝҷдёӘдҫӢеӯҗдёӯжҲ‘们иҖғиҷ‘дёҖз§ҚеҫҲжңүйҷҗзҡ„жғ…еҶөгҖӮжҲ‘们еҒҮи®ҫеӣҫдёӯжңү2nдёӘзӮ№пјҢжүҖжңүйЎ¶зӮ№зҡ„еәҰйғҪиҮіе°‘дёәnгҖӮеҸҜзҹҘеңЁиҝҷдәӣжқЎд»¶дёӢжҖ»еӯҳеңЁдёҖдёӘжңҖдјҳеҢ№й…ҚгҖӮжҲ‘们йҰ–е…Ҳз»ҷеҮәиҝҷдёӘдәӢе®һзҡ„иҜҒжҳҺпјҢ然еҗҺеұ•зӨәеҰӮдҪ•еҺ»дҝ®ж”№иҝҷдёӘиҜҒжҳҺд»ҺиҖҢеҫ—еҲ°дёҖдёӘжҹҘжүҫжңҖдјҳеҢ№й…Қзҡ„з®—жі•гҖӮ
иҜҒжҳҺйҮҮз”Ёзҡ„жҳҜжңҖеӨ§зҡ„еҸҚдҫӢгҖӮиҖғиҷ‘дёҖдёӘеӣҫG=(V,E)пјҢе…¶дёӯ|V|=2nжҜҸдёӘйЎ¶зӮ№зҡ„еәҰиҮіе°‘дёәnгҖӮеҰӮжһңn=1йӮЈд№ҲиҝҷдёӘеӣҫд»…д»…жңүдёҖжқЎиҫ№иҝһжҺҘдёӨдёӘйЎ¶зӮ№пјҢиҝҷе°ұжҳҜдёҖдёӘжңҖдјҳеҢ№й…ҚгҖӮеҒҮи®ҫn>1ж—¶дёҚеӯҳеңЁиҝҷж ·дёҖдёӘжңҖдјҳеҢ№й…ҚгҖӮиҖғиҷ‘еҲ°жңҖеӨ§еҢ№й…ҚMеұһдәҺEгҖӮз”ұеҒҮи®ҫзҹҘ|M|<nпјҢеҗҢж—¶з”ұдәҺд»»ж„ҸдёҖжқЎиҫ№иҮӘе·ұе°ұжҳҜдёҖдёӘеҢ№й…Қжҳҫ然жңү|M|вүҘ1гҖӮ既然MдёҚжҳҜе®Ңе…Ёзҡ„пјҲдёҚеҢ…жӢ¬жүҖжңүзҡ„зӮ№пјүпјҢйӮЈд№Ҳе°ұеӯҳеңЁиҮіе°‘дёӨдёӘдёҚзӣёйӮ»зӮ№v1е’Ңv2дёҚиў«еҢ…еҗ«еңЁMдёӯпјҲеҚіе®ғ们дёҚеҜ№еә”Mдёӯзҡ„дёҖжқЎиҫ№пјүгҖӮиҝҷдёӨдёӘзӮ№иҮіе°‘жңү2nдёӘдёҚеҗҢзҡ„иҫ№д»Һе®ғ们射еҮәгҖӮжүҖжңүиҝҷдәӣиҫ№йҖҡеҗ‘йӮЈдәӣеҢ…еҗ«еңЁMдёӯзҡ„йЎ¶зӮ№пјҢеҗҰеҲҷиҝҷж ·зҡ„иҫ№е°ұдёҚеҸҜиғҪиў«еҠ е…ҘеҲ°MдёӯгҖӮз”ұдәҺMдёӯиҫ№зҡ„ж•°зӣ®е°ҸдәҺnиҖҢдё”д»Һv1еҲ°v2жңү2nжқЎиҫ№дёҺд№ӢзӣёиҝһпјҢMдёӯиҮіе°‘жңүдёҖжқЎиҫ№пјҢеҒҮе®ҡдёә(u1,u2)пјҢдёҺд»Һv1еҲ°v2зҡ„дёүжқЎиҫ№зӣёиҝһгҖӮдёәдәҶдёҚеӨұдёҖиҲ¬жҖ§пјҢжҲ‘们еҒҮи®ҫиҝҷдёүжқЎиҫ№жҳҜ(u1,v1),(u1,v2)е’Ң(u2,v1)пјҲи§Ғеӣҫ6пјүгҖӮеҫҲе®№жҳ“еҸҜд»ҘзңӢеҲ°йҖҡиҝҮд»ҺMдёӯ移йҷӨ(u1,u2)еҠ дёҠиҫ№(u1,v2)е’Ң(u2,v1)жҲ‘们иғҪеӨҹеҫ—еҲ°дёҖдёӘжӣҙеӨ§зҡ„еҢ№й…ҚпјҢиҝҷдёҺд№ӢеүҚжңҖеӨ§зҡ„еҒҮи®ҫзӣёзҹӣзӣҫгҖӮ
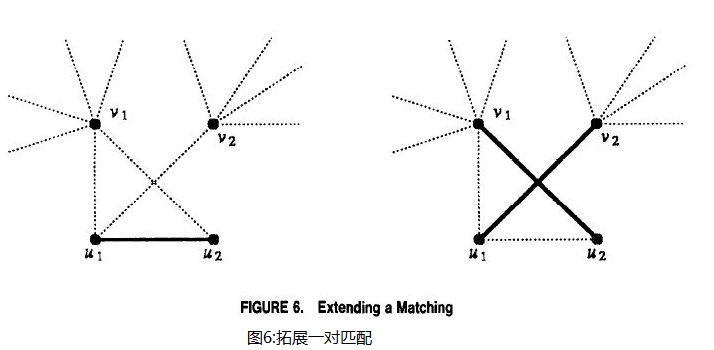
第дёҖзңјзңӢдёҠеҺ»иҝҷдёӘиҜҒжҳҺеҘҪеғҸж— жі•дә§з”ҹдёҖдёӘз®—жі•пјҢеӣ дёәиҜҒжҳҺжҳҜд»ҺдёҖдёӘжңҖеӨ§еҢ№й…ҚејҖе§Ӣзҡ„гҖӮдёҖж—ҰжҲ‘们зҹҘйҒ“еҰӮдҪ•еҺ»еҜ»жүҫиҝҷж ·дёҖдёӘеҢ№й…ҚжҲ‘们е°ұиғҪеӨҹи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ然иҖҢпјҢдҪҝз”ЁеҸҚиҜҒжі•йҖӮз”ЁдәҺд»»дҪ•жңҖеӨ§еҢ–зҡ„еҢ№й…ҚпјҢиҝҷйҮҢеұ•зӨәзҡ„еҸӘжҳҜз”ЁдәҺжңҖеӨ§еҢ№й…ҚиҖҢе·ІгҖӮжҹҘжүҫдёҖдёӘжңҖеӨ§еҢ–зҡ„еҢ№й…ҚиҰҒжҜ”жҹҘжүҫдёҖдёӘжңҖеӨ§еҢ№й…Қз®ҖеҚ•гҖӮжҲ‘们еҸӘйңҖиҰҒз®ҖеҚ•зҡ„ж·»еҠ дёҚзӣёиҝһзҡ„иҫ№пјҲеҚійӮЈдәӣжІЎжңүе…¬е…ұйЎ¶зӮ№зҡ„иҫ№пјүзӣҙеҲ°дёҚеӯҳеңЁиҝҷж ·зҡ„иҫ№зҡ„еҸҜиғҪгҖӮ然еҗҺжҲ‘们дҪҝз”ЁдёҠйқўжҸҸиҝ°зҡ„жӯҘйӘӨжҠҠиҜҘеҢ№й…ҚиҪ¬жҚўдёәдёҖдёӘжӣҙеӨ§зҡ„еҢ№й…ҚгҖӮйҖҡиҝҮдёҠйқўзҡ„иҜҒжҳҺжҲ‘们еҸҜд»ҘдёҚж–ӯеҸҚеӨҚжү§иЎҢзӣҙеҲ°жүҫеҲ°дёҖдёӘжңҖдјҳеҢ№й…ҚгҖӮ
е…¶д»–иҜҒжҳҺжҠҖе·§
еңЁиҝҷзҜҮи®әж–ҮдёӯжҲ‘们关注дәҺеҹәдәҺеҪ’зәіжі•зҡ„иҜҒжҳҺжҠҖе·§гҖӮиҝҷйҮҢжңүеҫҲеӨҡе…¶д»–зҡ„жҠҖе·§е’ҢжӣҙеӨҡзҡ„зұ»жҜ”пјҢдёҖдәӣдәӢеҫҲжҳҺжҳҫзҡ„пјҢдёҖдәӣеҲҷдёҚйӮЈд№ҲжҳҺжҳҫгҖӮи®ёеӨҡж•°еӯҰе®ҡзҗҶзҡ„иҜҒжҳҺжҳҜдҪҝз”ЁдёҖзі»еҲ—зҡ„еүҚжҸҗеҫ—еҲ°зҡ„пјҢиҝҷзӣҙжҺҘеҜ№еә”дәҺеңЁж ҮеҮҶи®ҫи®Ўе’Ңз»“жһ„еҢ–зј–зЁӢзҡ„жҖқжғігҖӮиҜҒжҳҺдёӯдҪҝз”ЁеҸҚиҜҒжі•еңЁз®—жі•и®ҫи®Ўдёӯд№ҹжңүзұ»дјјзҡ„ең°ж–№гҖӮз ”з©¶йӮЈдәӣдҪҝз”ЁвҖңзұ»дјјзҡ„и®әжҚ®вҖқиҜҒжҳҺзҡ„зұ»жҜ”жҳҜеҫҲжңүи¶Јзҡ„дёҖ件дәӢгҖӮ
жҲ‘们иҝҷйҮҢз®ҖиҰҒеҲ—еҮәеӣӣдёӘиҜҒжҳҺжҠҖе·§пјҲе…¶дёӯзҡ„дёүдёӘжҳҜеҹәдәҺеҪ’зәіжі•зҡ„пјүд»ҘеҸҠе®ғ们зҡ„зұ»жҜ”гҖӮжӣҙеӨҡзҡ„дҫӢеӯҗе’Ңзұ»жҜ”еҸҜд»ҘеңЁеҸӮиҖғж–ҮзҢ®[12]дёӯжүҫеҲ°гҖӮ
зј©еҮҸжі•
еңЁиҜҒжҳҺе®ҡзҗҶе’Ңи®ҫи®Ўз®—жі•ж—¶пјҢеңЁй—®йўҳд№Ӣй—ҙдҪҝз”Ёзј©еҮҸжҳҜдёҖз§ҚеҫҲејәеӨ§зҡ„жҠҖе·§гҖӮеҰӮжһңй—®йўҳAиў«жҢҮжҳҺжҳҜй—®йўҳBзҡ„зү№дҫӢпјҢйӮЈд№Ҳи§ЈеҶіBзҡ„з®—жі•еҸҜд»Ҙиў«еҪ“жҲҗдёҖдёӘй»‘зӣ’з”ЁжқҘи§ЈеҶіAгҖӮиҝҷдёӘжҠҖе·§еҜ№дәҺи§ЈеҶідёӢз•Ңе’ҢеҜ№й—®йўҳиҝӣиЎҢеҲҶзұ»д№ҹеҫҲжңүж•ҲпјҲдҫӢеҰӮNP-е®Ңе…Ёй—®йўҳпјүгҖӮеҰӮжһңе·ІзҹҘй—®йўҳAеҫҲйҡҫпјҢйӮЈд№Ҳй—®йўҳBд№ҹиҮіе°‘дёҖж ·йҡҫгҖӮ
еҸҢеҖҚеҪ’зәіжі•
иҝҷжҳҜдёҖз§ҚдҪҝз”ЁеҪ’зәіжі•й’ҲеҜ№дёҖж¬ЎеӨҡдҪҷдёҖдёӘеҸҳйҮҸзҡ„ж–№жі•гҖӮе®ғеҸҜз”ЁдәҺеңЁеҪ’зәіжі•жңҖдҪіеәҸеҲ—дёҚжҳҺзЎ®зҡ„жғ…еҶөпјҢеҗҢж—¶еңЁй’ҲеҜ№еҮ дёӘеҸҳйҮҸдҫқжҚ®дёҖдёӘзү№е®ҡзҡ„жӯҘйӘӨеңЁе…¶дёӯиҝӣиЎҢйҖүжӢ©ж—¶пјҢиҜҘж–№жі•д№ҹеҫҲе®№жҳ“дҪҝз”ЁеҲ°гҖӮдҫӢеҰӮпјҢеҰӮжһңй—®йўҳеҢ…еҗ«nдёӘзү©е“Ғе’ҢдёҖдёӘkз»ҙз©әй—ҙж—¶пјҢжҲ‘们еҸҜиғҪжғіеңЁз®—жі•жү§иЎҢж—¶еҮҸе°‘зү©е“Ғзҡ„ж•°йҮҸжҲ–иҖ…зү©е“Ғе°әеҜёзҡ„ж•°йҮҸгҖҗи§ҒдҫӢ4гҖ‘гҖӮ
йҖҶеҗ‘еҪ’зәіжі•
иҝҷдёӘжҠҖе·§еңЁж•°еӯҰдёӯдёҚз»ҸеёёдҪҝз”ЁпјҢдҪҶжҳҜеңЁи®Ўз®—жңә科еӯҰйўҶеҹҹеҚҙз»ҸеёёдҪҝз”ЁгҖӮжҷ®йҖҡзҡ„еҪ’зәіжі•йҖҡиҝҮд»ҺдёҖдёӘеҹәжң¬жғ…еҶө(n=1)ејҖе§Ӣ然еҗҺдёҚж–ӯжҺЁе№ҝд»ҺиҖҢиҰҶзӣ–жүҖжңүзҡ„иҮӘ然数гҖӮеҒҮи®ҫжҲ‘们жғіиҰҒйҖҶжҺЁгҖӮжҲ‘们еҒҮи®ҫе®ғеҜ№nжҲҗз«ӢжғіиҰҒиҜҒжҳҺе®ғеҜ№n-1д№ҹжҲҗз«ӢгҖӮжҲ‘们称иҝҷз§Қзұ»еһӢзҡ„иҜҒжҳҺдёәйҖҶеҗ‘еҪ’зәігҖӮдҪҶжҳҜпјҢд»Җд№ҲжҳҜжңҖеҹәжң¬зҡ„жғ…еҶөе‘ўпјҹжҲ‘们иғҪеӨҹд»ҺдёҖдёӘn=MпјҲMжҳҜдёҖдёӘйқһеёёеӨ§зҡ„ж•°пјүзҡ„еҹәжң¬жғ…еҶөејҖе§ӢгҖӮеҰӮжһңжҲ‘们иҜҒжҳҺе®ғеҜ№n=MжҲҗз«ӢпјҢ然еҗҺжҲ‘们е°ұеҸҜд»ҘдҪҝз”ЁйҖҶеҗ‘еҪ’зәіжі•д»ҺиҖҢиҜҒжҳҺеҜ№жүҖжңүе°ҸдәҺзӯүдәҺMзҡ„ж•°д№ҹжҲҗз«ӢгҖӮе°Ҫз®ЎйҖҡеёёиҝҷж ·жҳҜдёҚз¬ҰеҗҲиҰҒжұӮзҡ„пјҢдҪҶеңЁдёҖдәӣжғ…еҶөдёӢеҚҙжҳҜж»Ўи¶іиҰҒжұӮзҡ„гҖӮдҫӢеҰӮпјҢеҒҮи®ҫжҲ‘们жҠҠеҸҢеҖҚеҪ’зәіжі•з”ЁдәҺдёӨдёӘеҸҳйҮҸ(еҚіеӣҫдёӯзҡ„йЎ¶зӮ№ж•°е’Ңиҫ№ж•°)гҖӮжҲ‘们еҸҜд»ҘеҜ№дёҖдёӘеҸҳйҮҸеә”з”Ёжҷ®йҖҡзҡ„еҪ’зәіжі•пјҢеҰӮжһң第дәҢдёӘеҸҳйҮҸиғҪеӨҹеңЁз¬¬дёҖдёӘеҸҳйҮҸзҡ„иҢғеӣҙеҶ…жңүз•ҢпјҢйӮЈе°ұеҜ№з¬¬дәҢдёӘеҸҳйҮҸдҪҝз”ЁйҖҶеҗ‘еҪ’зәіжі•гҖӮдҫӢеҰӮпјҢеңЁдёҖдёӘжңүnдёӘйЎ¶зӮ№зҡ„жңүеҗ‘еӣҫдёӯжңҖеӨҡз”ұn*(n-1)жқЎиҫ№гҖӮеҜ№дәҺnжҲ‘们еҸҜд»ҘдҪҝз”Ёжҷ®йҖҡзҡ„еҪ’зәіжі•е№¶еҒҮи®ҫжүҖжңүзҡ„иҫ№йғҪжҳҜеӯҳеңЁзҡ„пјҲд№ҹе°ұжҳҜиҜҙжҲ‘们仅仅иҖғиҷ‘е®Ңе…ЁеӣҫпјүпјҢ然еҗҺеҜ№иҫ№зҡ„ж•°зӣ®дҪҝз”ЁйҖҶеҗ‘еҪ’зәіжі•гҖӮ
дёҖз§Қжӣҙеёёи§Ғзҡ„дҪҝз”ЁйҖҶеҗ‘еҪ’зәіжі•зҡ„еҒҡжі•еҰӮдёӢгҖӮд»…еҜ№nдёӯдёҖдёӘеҖјзҡ„еҹәжң¬жғ…еҶөиҜҒжҳҺиғҪйҷҗеҲ¶дәҺеҜ№йӮЈдәӣжҜ”иҜҘеҖјжӣҙе°Ҹзҡ„еҖјзҡ„иҜҒжҳҺпјҲиЎҘе……пјҡиҜҒжҳҺдәҶдёҖдёӘеҖјжҜ”е®ғе°Ҹзҡ„еҖјд№ҹе°ұеҸҜд»ҘиҜҒжҳҺдәҶпјүгҖӮеҒҮи®ҫжҲ‘们иғҪеӨҹзӣҙжҺҘеҜ№дёҖдёӘnеҸ–еҖјж— йҷҗзҡ„е®ҡзҗҶеҠ д»ҘиҜҒжҳҺгҖӮдҫӢеҰӮж— йҷҗйӣҶдёӯеҢ…еҗ«жүҖжңү2зҡ„е№ӮгҖӮйӮЈд№ҲжҲ‘们е°ұеҸҜд»ҘдҪҝз”ЁйҖҶеҗ‘еҪ’зәіжі•иҰҶзӣ–nзҡ„жүҖжңүеҖјгҖӮиҝҷжҳҜдёҖз§Қжңүж•ҲиҜҒжҳҺжҠҖе·§пјҢеӣ дёәеҜ№дәҺжҜҸдёӘnеҸ–еҖјеңЁеҹәжң¬йӣҶдёӯйғҪеӯҳеңЁдёҖдёӘжҜ”е…¶еӨ§зҡ„еҖјпјҲз”ұдәҺйӣҶеҗҲејҸж— йҷҗзҡ„пјүгҖӮ
дҪҝз”Ёиҝҷз§ҚжҠҖе·§зҡ„дёҖдёӘйқһеёёеҘҪзҡ„дҫӢеӯҗжҳҜеңЁз®—жңҜе№іеқҮдёҚзӯүејҸе’ҢеҮ дҪ•е№іеқҮдёҚзӯүејҸпјҲжҹҜиҘҝдёҚзӯүејҸпјүдёӯз”ЁеҲ°зҡ„дјҳйӣ…зҡ„иҜҒжҳҺж–№жі•пјҲдҫӢеӯҗи§Ғ[3]пјүгҖӮеҪ“иҜҒжҳҺж•°еӯҰе®ҡзҗҶж—¶пјҢд»ҺnеҲ°n-1еҫҖеҫҖдёҚжҜ”д»Һn-1еҲ°nз®ҖеҚ•пјҢеҗҢж—¶иҜҒжҳҺдёҖдёӘж— йҷҗйӣҶзҡ„еҹәжң¬жғ…еҶөиҰҒжҜ”дёҖдёӘз®ҖеҚ•йӣҶзҡ„еҹәжң¬жғ…еҶөеӣ°йҡҫзҡ„еӨҡгҖӮеңЁи®ҫи®Ўз®—жі•ж—¶пјҢдёҺд№ӢзӣёеҸҚзҡ„жҳҜпјҢд»ҺnеҲ°n-1жҖ»жҳҜеҫҲе®№жҳ“пјҢд№ҹе°ұжҳҜй’ҲеҜ№жӣҙе°Ҹзҡ„иҫ“е…Ҙ规模зҡ„й—®йўҳжұӮи§ЈгҖӮдҫӢеҰӮпјҢжҲ‘们еҸҜд»Ҙеј•е…ҘйӮЈдәӣдёҚеҪұе“Қиҫ“еҮәзҡ„еҒҮж•°жҚ®гҖӮз»“и®әжҳҜпјҢеңЁеҫҲеӨҡжғ…еҶөдёӢдёҚж №жҚ®иҫ“е…ҘйҮҸзҡ„еҗ„з§ҚеӨ§е°ҸиҖҢжҳҜж №жҚ®д»Һж— йҷҗйӣҶдёӯеҸ–еҫ—зҡ„еӨ§е°ҸжқҘи®ҫи®Ўз®—жі•еҫҖеҫҖжҳҜе……еҲҶзҡ„гҖӮжңҖеёёи§Ғзҡ„дҪҝз”Ёиҝҷз§ҚеҺҹзҗҶзҡ„еҒҡжі•жҳҜеңЁи®ҫи®Ўз®—жі•ж—¶д»…иҖғиҷ‘жҳҜ2зҡ„е№Ӯзҡ„nзҡ„еӨ§е°Ҹиҫ“е…ҘгҖӮиҝҷдҪҝеҫ—и®ҫи®Ўжӣҙз®ҖжҙҒд№ҹжҺ’йҷӨдәҶеҫҲеӨҡжқӮд№ұзҡ„з»ҶиҠӮгҖӮеҫҲжҳҫ然иҝҷдәӣз»ҶиҠӮжңҖз»Ҳд№ҹйңҖиҰҒиў«и§ЈеҶіпјҢдҪҶжҳҜе®ғ们еҫҖеҫҖеҫҲе®№жҳ“еӨ„зҗҶгҖӮдҫӢеҰӮеңЁжңҖиҝ‘еҜ№й—®йўҳдёӯпјҢжҲ‘们дҪҝз”ЁnжҳҜ2зҡ„е№Ӯзҡ„еҒҮи®ҫгҖӮ
жҳҺжҷәзҡ„йҖүжӢ©еҪ’зәіжі•зҡ„еҹәжң¬жғ…еҶө
еҫҲеӨҡйҖ’еҪ’з®—жі•пјҲдҫӢеҰӮеҝ«жҺ’пјүеҜ№дәҺе°Ҹй—®йўҳиҖҢиЁҖж•Ҳжһң并дёҚжҳҜеҫҲеҘҪгҖӮеҪ“й—®йўҳиў«з®ҖеҢ–дёәдёҖдёӘе°Ҹй—®йўҳж—¶пјҢеҸҜд»ҘдҪҝз”ЁеҸҰдёҖз§Қз®ҖеҚ•зҡ„з®—жі•пјҲдҫӢеҰӮжҸ’е…ҘжҺ’еәҸпјүгҖӮд»ҺеҪ’зәіжі•жқҘзңӢпјҢиҝҷдёӯеҒҡжі•з¬ҰеҗҲйҖүжӢ©дёҖз§Қn=k(kдҫқжҚ®й—®йўҳжқҘе®ҡ)еҹәжң¬жғ…еҶө然еҗҺдҪҝз”ЁдёҖз§ҚзӣҙжҺҘзҡ„жҠҖе·§жқҘи§ЈеҶіиҝҷз§Қеҹәжң¬жғ…еҶөзҡ„жҖқжғігҖӮжңүдәӣдҫӢеӯҗдёӯиҝҷз§ҚеҒҡжі•з”ҡиҮіиғҪеӨҹж”№е–„з®—жі•зҡ„жёҗиҝ‘иҝҗиЎҢж—¶й—ҙ[12]гҖӮ
з»“и®ә
жҲ‘们еұ•зӨәдәҶдёҖз§Қи§ЈйҮҠе’ҢдҪҝз”Ёз»„еҗҲз®—жі•и®ҫи®Ўзҡ„ж–№жі•гҖӮдҪҝз”Ёиҝҷз§Қжҷ®йҖҡзҡ„ж–№жі•зҡ„еҘҪеӨ„жҳҜдёӨж–№йқўзҡ„гҖӮйҰ–е…ҲпјҢе®ғз»ҷз®—жі•и®ҫи®ЎиҖ…们жҸҗдҫӣдәҶдёҖдёӘжӣҙеҠ з»ҹдёҖзҡ„вҖңиҝӣж”»и·ҜзәҝвҖқпјҲеӨ„зҗҶй—®йўҳж–№жі•пјүгҖӮз»ҷе®ҡдёҖдёӘеҫ…и§ЈеҶізҡ„й—®йўҳпјҢдёҖдёӘдәәеҸҜд»ҘйҖҡиҝҮдҪҝз”Ёж–Үз« дёӯжҸҸиҝ°е’ҢйҳҗжҳҺзҡ„жҠҖе·§е°қиҜ•жүҫеҲ°дёҖдёӘи§Јжі•гҖӮз”ұдәҺиҝҷдәӣжҠҖе·§жңүдёҖдәӣзӣёдјјзҡ„ең°ж–№пјҲд№ҹе°ұжҳҜж•°еӯҰеҪ’зәіжі•пјүпјҢеҜ№е®ғ们全йғЁиҝӣиЎҢе°қиҜ•зҡ„иҝҮзЁӢиғҪеӨҹиў«жӣҙеҘҪзҡ„зҗҶи§Јд№ҹжӣҙе®№жҳ“иҝӣиЎҢгҖӮ第дәҢзӮ№пјҢе®ғжҸҗдҫӣдәҶдёҖз§Қи§ЈйҮҠзҺ°жңүз®—жі•зҡ„зҡ„жӣҙз»ҹдёҖзҡ„ж–№жі•пјҢдҪҝеҫ—еӯҰз”ҹиғҪжӣҙеӨҡзҡ„еҸӮдёҺеҲӣйҖ иҝҮзЁӢгҖӮеҗҢж—¶пјҢеҜ№дәҺз®—жі•жӯЈзЎ®жҖ§зҡ„иҜҒжҳҺеңЁжҸҸиҝ°дёӯеҚ жӣҙйҮҚиҰҒзҡ„йғЁеҲҶгҖӮжҲ‘们зӣёдҝЎиҝҷз§Қж–№жі•иғҪеӨҹеҢ…еҗ«еңЁеҜ№з»„еҗҲз®—жі•иҝӣиЎҢж•ҷеӯҰд№ӢдёӯгҖӮ
жң¬ж–ҮжқҘжәҗдәҺпјҡhttp://blog.prosight.me/index.php/2011/07/739


- 2011-12-29 13:21
- жөҸи§Ҳ 556
- иҜ„и®ә(0)
- жҹҘзңӢжӣҙеӨҡ
еҸ‘иЎЁиҜ„и®ә

зӣёе…іжҺЁиҚҗ
дҪҝз”ЁеҪ’зәіжі•и®ҫи®Ўз®—жі• и®әж–Үзҝ»иҜ‘,иҮӘе·ұзҝ»иҜ‘зҡ„пјҢиғҪеҠӣжңүйҷҗ
еҜ№з®—жі•дёӯзҡ„еҪ’зәіжі•иҝӣиЎҢдәҶиҜҰе°Ҫзҡ„д»Ӣз»ҚпјҢжңүз®—жі•зҡ„дјӘд»Јз Ғд»ҘеҸҠеӨҚжқӮеәҰеҲҶжһҗ
з®—жі•и®ҫи®ЎжҠҖе·§дёҺеҲҶжһҗпјҡ第дә”и®І еҪ’зәіжі•.ppt
CиҜӯиЁҖеҪ’зәіз®—жі•пјҢзҝ»зЎ¬еёҒпјҢеҘҮеҒ¶ж•° жңүNдёӘзЎ¬еёҒпјҲNдёәеҒ¶ж•°пјүжӯЈйқўжңқдёҠжҺ’жҲҗдёҖжҺ’пјҢжҜҸж¬Ўе°ҶN-1дёӘзЎ¬еёҒзҝ»иҝҮжқҘж”ҫеңЁеҺҹдҪҚзҪ®пјҢдёҚж–ӯең°йҮҚеӨҚдёҠиҝ°иҝҮзЁӢпјҢзӣҙеҲ°жңҖеҗҺе…ЁйғЁзЎ¬еёҒзҝ»жҲҗеҸҚйқўжңқдёҠдёәжӯўгҖӮи®ҫи®ЎзЁӢеәҸи®©и®Ўз®—жңәжҠҠзҝ»еёҒзҡ„жңҖз®ҖиҝҮзЁӢд»ҘеҸҠзҝ»еёҒж¬Ўж•°...
еңЁиҝӣиЎҢеҪ’зәіжҺЁзҗҶж—¶пјҢеҰӮжһңйҖҗдёӘиҖғеҜҹдәҶжҹҗзұ»дәӢ件зҡ„жүҖжңүеҸҜиғҪжғ…еҶөпјҢеӣ иҖҢеҫ—еҮәдёҖиҲ¬з»“и®әпјҢйӮЈд№Ҳиҝҷз»“и®әжҳҜеҸҜйқ зҡ„пјҢиҝҷз§ҚеҪ’зәіж–№жі•еҸ«еҒҡжһҡдёҫжі•пјҢжң¬з®—жі•з”ұC++е®һзҺ°
еҲ°з¬¬4ж„Ҹдёәд»Ӣз»ҚжҖ§еҶ…е®№пјҢж¶үеҸҠж•°еӯҰеҪ’зәіжі•гҖҒз®—жі•еҲҶжһҗгҖҒж•°жҚ®з»“жһ„зӯүеҶ…е®№пјӣ第5з« жҸҗеҮәдәҶдёҺеҪ’зәіиҜҒжҳҺиҝӣиЎҢзұ»жҜ”зҡ„ з®—жі•и®ҫи®ЎжҖқжғіпјӣ第6жӢҝеҲ°з¬¬9е®ЈиЁҖеҲҶеҲ«з»ҷеҮәдәҶ4дёӘйўҶеҹҹзҡ„з®—жі•пјҢеҰӮеәҸеҲ—е’ҢйӣҶеҗҲзҡ„з®—жі•гҖҒеӣҫз®—жі•гҖҒеҮ дҪ•з®—жі•гҖҒд»Јж•° е’Ңж•°еҖј...
з®—жі•и®ҫи®ЎдёҺеҲҶжһҗPPTгҖӮжңүеҪ’зәіжі•гҖҒеҲҶжІ»гҖҒиҙӘеҝғз®—жі•гҖҒеҠЁжҖҒ规еҲ’зӯүгҖӮ
йҖ’еҪ’е°Ҹз»“ вҖўдјҳзӮ№пјҡз»“жһ„жё…жҷ°пјҢеҸҜиҜ»жҖ§ејәпјҢиҖҢдё”е®№жҳ“з”Ёж•°еӯҰеҪ’зәіжі•жқҘиҜҒжҳҺз®—жі•зҡ„жӯЈзЎ®жҖ§пјҢеӣ жӯӨе®ғдёәи®ҫи®Ўз®—жі•гҖҒи°ғиҜ•зЁӢеәҸеёҰжқҘеҫҲеӨ§ж–№дҫҝгҖӮ вҖўзјәзӮ№пјҡйҖ’еҪ’з®—жі•зҡ„иҝҗиЎҢж•ҲзҺҮиҫғдҪҺпјҢж— и®әжҳҜиҖ—иҙ№зҡ„и®Ўз®—ж—¶й—ҙиҝҳжҳҜеҚ з”Ёзҡ„еӯҳеӮЁз©әй—ҙйғҪжҜ”йқһйҖ’еҪ’...
иҝҷжң¬д№Ұеҹәжң¬еҢ…жӢ¬йӮЈдәӣз»Ҹе…ёз®—жі•пјҢжҜ”еҰӮеҪ’зәіжі•пјҢеҲҶжІ»пјҢеҠЁжҖҒ规еҲ’зӯүзӯүпјҢеҰӮжһңжҳҜжғіеӯҰд№ дёҖдәӣз®—жі•зҡ„иҜқпјҢиҝҷжң¬д№Ұзҡ„дёӘдёҚй”ҷзҡ„йҖүжӢ©гҖӮ
е…Ёд№Ұе…ұеҲҶ12з« пјҢжҳҜжҢүз…§йўҶеҹҹиҝӣиЎҢеҲҶзұ»зҡ„пјҡ第1з« еҲ°з¬¬4з« дёәд»Ӣз»ҚжҖ§еҶ…е®№пјҢж¶үеҸҠж•°еӯҰеҪ’зәіжі•гҖҒз®—жі•еҲҶжһҗгҖҒж•°жҚ®з»“жһ„зӯүеҶ…е®№пјӣ第5з« жҸҗеҮәдәҶдёҺеҪ’зәіиҜҒжҳҺиҝӣиЎҢзұ»жҜ”зҡ„з®—жі•и®ҫи®ЎжҖқжғіпјӣ第6з« еҲ°з¬¬9з« еҲҶеҲ«з»ҷеҮәдәҶеҮ дёӘйўҶеҹҹзҡ„з®—жі•пјҢеҰӮеәҸеҲ—е’ҢйӣҶеҗҲ...
е…Ёд№Ұе…ұеҲҶ12з« пјҢжҳҜжҢүз…§йўҶеҹҹиҝӣиЎҢеҲҶзұ»зҡ„пјҡ第1з« еҲ°з¬¬4з« дёәд»Ӣз»ҚжҖ§еҶ…е®№пјҢж¶үеҸҠж•°еӯҰеҪ’зәіжі•гҖҒз®—жі•еҲҶжһҗгҖҒж•°жҚ®з»“жһ„зӯүеҶ…е®№пјӣ第5з« жҸҗеҮәдәҶдёҺеҪ’зәіиҜҒжҳҺиҝӣиЎҢзұ»жҜ”зҡ„з®—жі•и®ҫи®ЎжҖқжғіпјӣ第6з« еҲ°з¬¬9з« еҲҶеҲ«з»ҷеҮәдәҶеҮ дёӘйўҶеҹҹзҡ„з®—жі•пјҢеҰӮеәҸеҲ—е’ҢйӣҶеҗҲ...
еҪ’зәіеҮәйў‘еәҰз»ҹи®Ўжі•гҖҒйў‘еәҰдј°з®—жі•гҖҒйў‘еәҰжңӘзҹҘж•°жі•гҖҒеҲ—дёҫйў‘еәҰеҪ’зәіжі•гҖҒйў‘еәҰжңҹжңӣеҖјжі•гҖҒжү©еұ•йҖ’еҪ’иҝӯд»Јжі•гҖҒдёҠдёӢйҷҗзҢңжөӢжі•зӯүеҮ з§Қж №жҚ®з®—жі•зү№жҖ§жұӮи§Јж—¶й—ҙеӨҚжқӮеәҰзҡ„ж–№жі•.иҝҷдәӣж–№жі•ж¶өзӣ–дәҶеӨ§еӨҡзұ»з®—жі•,ж— и®әжҳҜеңЁиҪҜ件и®ҫи®Ў,иҝҳжҳҜеңЁж•ҷеӯҰе®һи·өдёӯ,...
1 гҖҠи®Ўз®—жңәзЁӢеәҸи®ҫи®ЎгҖӢдёӯеёёз”Ёз®—жі•еӨҚд№ дёҖгҖҒеёёз”Ёз®—жі•жңү 8 дёӘж–№йқўпјҡ 1гҖҒйҖ’жҺЁз®—жі•пјҲзә§ж•°гҖҒж•°еҲ—жұӮе’ҢгҖҒдәҢеҲҶжі•гҖҒжўҜеҪўжі•гҖҒз©·дёҫжі• зӯүпјү 2гҖҒжҺ’еәҸз®—жі•пјҲйҖүжӢ©жі•жҺ’еәҸгҖҒеҶ’жіЎжі•пјү 3гҖҒжҹҘжүҫз®—жі•пјҲйЎәеәҸжҹҘжүҫ гҖҒжҠҳеҚҠжҹҘжүҫгҖҒз»ҹи®ЎгҖҒжұӮе’ҢгҖҒ...
第5з« еҪ’зәіжі• 第6з« еҲҶжІ» 第7з« еҠЁжҖҒ规еҲ’ 第дёүйғЁеҲҶ жңҖе…ҲеүІжҠҖжңҜ 第8з« еҝөеҝғз®—жі• 第9з« еӣҫзҡ„йҒҚеҺҶ 第еӣӣйғЁ й—®йўҳеӨҚжқӮжҖ§ 第10з« NPе®Ңе…Ёй—®йўҳ 第11з« и®Ўз®—жңәжқӮжҖ§еј•и®ә 第12з« дёӢз•Ң 第дә”йғЁеҲҶ е…ӢжңҚеӣ°йҡҫжҖ§ 第13з« еӣһжәҜ...
дёҖеҘ—дёҺгҖҠз®—жі•и®ҫи®ЎжҠҖе·§дёҺеҲҶжһҗгҖӢй…ҚеҘ—дҪҝз”Ёзҡ„PPTпјҢж¶өзӣ–еј•иЁҖгҖҒз®—жі•еҲҶжһҗеҹәжң¬жҰӮеҝөгҖҒж•°еӯҰйў„еӨҮзҹҘиҜҶгҖҒеҪ’зәіжі•зӯүйғЁеҲҶ
е…Ёд№Ұе…ұеҲҶ12з« пјҢжҳҜжҢүз…§йўҶеҹҹиҝӣиЎҢеҲҶзұ»зҡ„пјҡ第1з« еҲ°з¬¬4з« дёәд»Ӣз»ҚжҖ§еҶ…е®№пјҢж¶үеҸҠж•°еӯҰеҪ’зәіжі•гҖҒз®—жі•еҲҶжһҗгҖҒж•°жҚ®з»“жһ„зӯүеҶ…е®№пјӣ第5з« жҸҗеҮәдәҶдёҺеҪ’зәіиҜҒжҳҺиҝӣиЎҢзұ»жҜ”зҡ„з®—жі•и®ҫи®ЎжҖқжғіпјӣ第6з« еҲ°з¬¬9з« еҲҶеҲ«з»ҷеҮәдәҶеҮ дёӘйўҶеҹҹзҡ„з®—жі•пјҢеҰӮеәҸеҲ—е’ҢйӣҶеҗҲ...
з®—жі•еј•и®әпјҡдёҖз§ҚеҲӣйҖ жҖ§ж–№жі• дёӯж–ҮзүҲ з”өеӯҗе·ҘдёҡеҮәзүҲзӨҫ зӢ¬е…·зү№иүІең°е°Ҷж•°еӯҰеҪ’зәіжі•дҪңдёәи®Іи§Је’Ңи®ҫи®Ўз®—жі•зҡ„е·Ҙе…·
з®—жі•и®ҫи®ЎдёҺеҲҶжһҗиҜҫзЁӢPPT 第1з« з®—жі•еҲҶжһҗеҹәжң¬жҰӮеҝө 第4з« е Ҷе’ҢдёҚзӣёдәӨж•°жҚ®з»“жһ„ 第5з« еҪ’зәіжі• 第6з« еҲҶжІ» 第7з« еҠЁжҖҒ规еҲ’ 第8з« иҙӘеҝғз®—жі• 第13з« еӣһжәҜжі•
иө„жәҗд»Ӣз»Қпјҡжң¬д№Ұд»Ӣз»ҚдәҶеёёз”Ёз®—жі•и®ҫи®ЎгҖӮеҢ…жӢ¬еҲ—дёҫжі•пјҢйҖ’жҺЁжі•пјҢйҖ’еҪ’з®—жі•пјҢеҪ’зәіжі•пјҢжҺ’еәҸз®—жі•пјҢиҙӘе©Әз®—жі•пјҢиҝҳжңүдёҖдәӣдҫӢзЁӢгҖӮиө„жәҗдҪңиҖ…пјҡ